Linux命令行与shell腳本編程大全
原书籍《Linux命令行与shell腳本編程大全》
摘要: linux number one
Table of Contents
- 1. linux入门
- 2. 走进shell
- 3. 基本shell命令
- 4. 其他shell命令
- 5. 理解shell
- 6. 环境变量
- 7. linux文件权限
- 8.管理文件系统
- 9. 安装软件程序
- 10. 使用编辑器
- 11.基本脚本
- 12. 使用结构化命令
- 13. for 循环
- 14. 处理用户输入
- 15. 呈现数据
- 16. 控制脚本
- 17. 创建函数
- 18. 图形化界面中脚本编程
- 19.初识sed和gawk
- 20.正则表达式
- AppendIndex
1. linux入门
linux是一款开源操作系统统称,其有很多发行版本,像ubuntu..,它的核心是其内核,早期由linus torvalds开发

内核主要负责以下四种功能:
系统内存管理
软件程序管理
linux管理所有运行程序的进程.内核启动时会将init进程加载到虚拟内存,一些发行版本在/etc/inittab位置进行管理自启动进程,ubuntu则是在/etc/init.d或者/etc/rcX.d,/etc/rcX.d,X是某一特定是某一特定类型的进程,如下rc0.d/,rc1.d/,rc2.d/,rc3.d/,rc4.d/,rc5.d/,rc6.d/,rcS.d/运行级为1时,只启动基本的系统进程以及一个控制台终端进程。称之为单用户模式。单用户模式通常用来在系统有问题时进行紧急的文件系统维护。在这种模式下,仅有一个人(通常是系统管理员)能登录到系统上操作数据(这块部分以后涉及再补充也来的急,别深究)硬件设备管理
两种方式将驱动程序插入到系统内核- 编译进内核的设备驱动代码
- 以前加入新的驱动要重新编译内核,效率低下
- 可插入内核的设备驱动模块
可插拔式内核驱动,Linux系统将硬件设备当成特殊的文件,称为设备文件。设备文件有3种分类:- 字符型设备文件
- 块设备文件
- 网络设备文件
- 编译进内核的设备驱动代码
文件系统管理
linux自有的诸多文件系统外,Linux还支持从其他操作系统(比如Microsoft Windows)采用的文件系统中读写数据。内核必须在编译时就加入对所有可能用到的文件系统的支持
2. 走进shell
在图形化桌面出现之前,与Unix(linux是兼容unix操作系统)系统进行交互的唯一方式就是借助由shell所提供的文本命令行界面(command line interface,CLI),是一种同Linux系统交互的直接接口
3. 基本shell命令
3.1 启动shell
/etc/passwd包含用户的基本信息,如下输出
christine: x :501:501:Christine Bresnahan:/home/christine:/bin/bash位置以此类推是用户名,密码,UID,GID,用户文本描述,家目录,默认启动启动bash作为自己的shell命令(第七章将有详细描述),目前绝大多数linux发行版将密码放在/etc/shadow目录下,普通方式是无法直接看到的
3.2 bash 手册
linux自带命令手册,方便用户查看相关命令的具体选项和参数。在手册左上角括号内的数字表明对应的内容区域。每个内容区域都分配了一个数字,
| 序号 | 解释 |
|---|---|
| 1 | 可执行程序或shell命令 |
| 2 | 系统调用 |
| 3 | 库调用 |
| 4 | 特殊文件 |
| 5 | 文件格式与约定 |
| 6 | 游戏 |
| 7 | 概览,约定及杂项 |
| 8 | 超级用户和系统管理员命令 |
| 9 | 内核例程 |
如果你忘了命令的关键字那么可以使用man -k的方式查找命令,比如mkdir,就可以使用man -k mkdir,就可以检索出与mkdir相关的命令.
包括对系统主机名的概述。要想查看所需要的页面,输入man section linux-CMD-sytax。对手册页中的第1部分而言,就是输入man 1 hostname。对于手册页中的第7部分,就是输入man 7 hostname
手册页不是唯一的参考资料。还有另一种叫作info页面的信息。可以输入info info来了解info页面的相关内容。
3.4 文件系统
简单理解,linux文件系统跟windows的文件布局是不一样的。
linux 文件系统
目录 描述 /bin 二进制目录,存放许多用户级的GNU工具 /boot 启动目录,存放启动文件 /dev 设备目录,Linux在这里创建设备节点 /etc 系统配置文件目录 /home 主目录,Linux在这里创建用户目录 /lib 库目录,存放系统和应用程序的库文件 /media 媒体目录,可移动媒体设备的常用挂载点 /mnt 挂载目录,另一个可移动媒体设备的常用挂载点 /opt 可选目录,常用于存放第三方软件包和数据文件 /proc 进程目录,存放现有硬件及当前进程的相关信息 /root root用户的主目录 /sbin 系统二进制目录,存放许多GNU管理员级工具 /run 运行目录,存放系统运作时的运行时数据 /srv 服务目录,存放本地服务的相关文件 /sys 系统目录,存放系统硬件信息的相关文件 /tmp 临时目录,可以在该目录中创建和删除临时工作文件 /usr 用户二进制目录,大量用户级的GNU工具和数据文件都存储在这里 /var 可变目录,用以存放经常变化的文件,比如日志文件 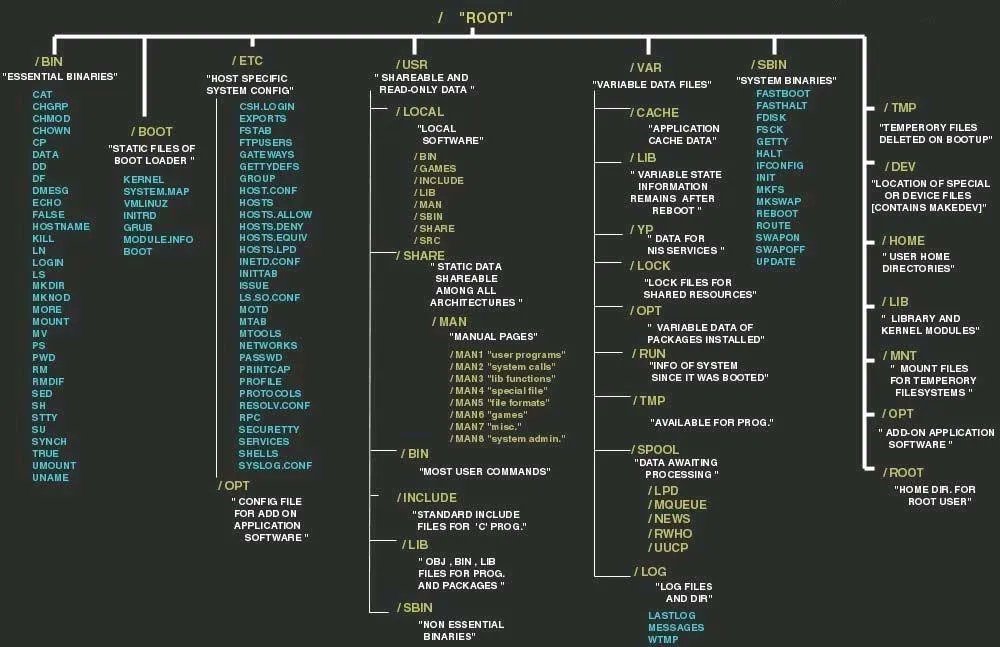
遍历目录(cd命令)
需要你知道文件树状结构,这样才能知道你将访问文件的具体位置,无论是相对路径还是绝对路径cd命令,这时要注意文件系统的相对路径和绝对路径问题,linux通过这两种方式确定目录位置,符号/是表示根目录- 绝对路径 通过从root目录开始一层一层的进行访问,最终访问到目标文件或者目录,
/bin/bash从根目录定位到bash - 相对路径
./当前目录../上层目录~/表示当前用户home目录
cd ~/ # 进到对应账号的home目录下 cd /home/kirkzhang #使用绝对路径进入家目录- 绝对路径 通过从root目录开始一层一层的进行访问,最终访问到目标文件或者目录,
目录列表(ls命令)
ls按照字母序列,参数-l显示长列表,更多参数查看ls手册,另一个替换命令getfacl查询问价权限- 问号(?)代表一个字符
- 星号(*)代表零个或多个字符
文件链接
- 软连接
当我们需要相同文件时,不必要在每个文件夹下都放一份文件夹,只需要使用软链接
ls -s /usr/local/mysql/bin/mysql /usr/bin - 硬链接
- 软连接
4. 其他shell命令
4.1 监控程序
4.1.1 ps查看进程
ps 选项
-A 显示所有进程
-N 显示与指定参数不符的所有进程
-a 显示除控制进程(session leader)和无终端进程外的所有进程
-d 显示除控制进程外的所有进程
-e 显示所有进程
-C cmdlist 显示包含在cmdlist列表中的进程
-G grplist 显示组ID在grplist列表中的进程
-U userlist 显示属主的用户ID在userlist列表中的进程
-g grplist 显示会话或组ID在grplist列表中的进程②
-p pidlist 显示PID在pidlist列表中的进程
-f 完整格式输出命令输出关键词意义
| 名词 | 解释 |
|---|---|
| UID | 启动这些进程的用户 |
| PID | 进程的ID |
| PPID | 父进程的进程号(如果该进程是由另一个进程启动的) |
| C | 进程生命周期中的CPU利用率 |
| STIME | 进程启动时的系统时间 |
| TTY | 进程启动时的终端设 |
| TIME | 运行进程需要的累计CPU时间 |
| CMD | 启动的程序名称 |
4.1.2 top实时监控
- 第一行:当前时间,系统运行时间,登录用户数,系统的平均负载(15分钟的参数越大且超过2,说明有问题)
- 第二行:进程状态
- 第三行:CPU相关数值,使用率
| 名词 | 解释 |
|---|---|
| PID | 进程的ID |
| USER | 进程属主的名字 |
| PR | 进程的优先级 |
| NI | 进程的谦让度度 |
| VIRT | 进程占用的虚拟内存总量 |
| RES | 进程占用的物理内存总量 |
| SHR | 进程和其他进程共享的内存总量 |
| S | 进程的状态(D代表可中断的休眠状态,R代表在运行状态,S代表休眠状态,T代表 跟踪状态或停止状态,Z代表僵化状态) |
| %CPU | 进程使用的CPU时间比例 |
| %MEM | |
| TIME+ | 自进程启动到目前为止的CPU时间总量 |
| COMMAND | 进程所对应的命令行名称,也就是启动的程序名 |
4.1.3 kill结束进程
| 信号 | 名称 | 描述 |
|---|---|---|
| 1 | HUP | 挂起 |
| 2 | INT | 中断 |
| 3 | QUIT | 退出 |
| 9 | KILL | 无条件终止 |
| 11 | SEGV | 段错误 |
| 15 | TERM | 尽可能终止 |
| 17 | STOP | 无条件终止 |
| 18 | TSTP | 停止或暂停,但在后台运行 |
| 19 | CONT | 在STOP或TSTP之后恢复执行 |
4.1.4 系统performance监控
这个要下载sysstat程序
- iostat - reports CPU statistics and input/output statistics for block devices and partitions.
- mpstat - Processors Statistics
`mpstat -P ALL` #所有processor
`mpstat -P ALL 2 5` #迭代五次间隔两秒- pidstat - Process and Kernel Threads Statistics
- tapestat - reports statistics for tape drives connected to the system
- cifsiostat - reports CIFS statistics.
4.2 磁盘空间监控
4.2.1 mount挂在存储媒体
mount提供如下信息媒体设备名,挂载点,文件类型,访问方式
#将A设备挂在到B目录上,type 参数指定了磁盘被格式化的文件系统类型,如`vfat`,`iso9660`,`ntfs`,例如`mount -t vfat /dev/sdb1 /media/ disk`
mount -t type A B mount参数列表,详情见man手册,或者如下
参 数 描 述 -a 挂载/etc/fstab文件中指定的所有文件系统 -f 使 mount 命令模拟挂载设备,但并不真的挂载 -F 和 -a 参数一起使用时,会同时挂载所有文件系统 -v 详细模式,将会说明挂载设备的每一步 -I 不启用任何/sbin/mount.filesystem下的文件系统帮助文件 -l 给ext2、ext3或XFS文件系统自动添加文件系统标签 -n 挂载设备,但不注册到/etc/mtab已挂载设备文件中 -p num进行加密挂载时,从文件描述符 num 中获得密码短语 -s 忽略该文件系统不支持的挂载选项 -r 将设备挂载为只读的 -w 将设备挂载为可读写的(默认参数) -L label 将设备按指定的 label 挂载 -U uuid 将设备按指定的 uuid 挂载 -O 和 -a 参数一起使用,限制命令只作用到特定的一组文件系统上 -o 给文件系统添加特定的选项 -o参数允许在挂载文件系统时添加一些以逗号分隔的额外选项。以下为常用的选项ro #只读挂载 rw #读写挂载 user #允许普通用户挂在 loop #挂载一个文件 check=none #挂载时进行完整性校验
4.2.2 unmount 卸载设备
unmount [directory | device] # //卸载文件应在外侧目录完成,命令行提示符仍然在挂载设备的文件系统目录中,`umount` 命令无法卸载该镜像4.2.3 df 查看磁盘情况
命令格式: df [OPTION]… [FILE]…
-h # 以M,G描述问价大小
-a, --all
# include pseudo, duplicate, inaccessible file systems
-B, --block-size=SIZE
# scale sizes by SIZE before printing them; e.g., '-BM' prints sizes in units of
# 1,048,576 bytes; see SIZE format below
-h, --human-readable
# print sizes in powers of 1024 (e.g., 1023M)
-H, --si
#print sizes in powers of 1000 (e.g., 1.1G)
-i, --inodes
#list inode information instead of block usage
-k like --block-size=1K
-l, --local
#limit listing to local file systems
--no-sync
#do not invoke sync before getting usage info (default)
--output[=FIELD_LIST]
#use the output format defined by FIELD_LIST, or print all fields if FIELD_LIST is omit‐ted.
-P, --portability
#use the POSIX output format
--sync invoke sync before getting usage info
--total
#elide all entries insignificant to available space, and produce a grand total
-t, --type=TYPE
#limit listing to file systems of type TYPE
-T, --print-type
#print file system type
-x, --exclude-type=TYPE
#limit listing to file systems not of type TYPE
-v (ignored)
--help display this help and exit
--version
#output version information and exit
4.2.4 du 查看磁盘占用空间
-c #显示所有已列出文件总的大小(还是不宜读)
-h #按用户易读的格式输出大小,即用K替代千字节
-s #显示每个输出参数的总计
-d # 限制查询深度4.3 处理文件
4.3.1 sort - 文件排序
-n #sort命令会把数字当做字符来执行标准的字符排序,解决
-M #按照月份排序
-k #和`-t`参数在对按字段分隔的数据进行排序时非常有用`sort -t ':' -k 3 -n /etc/passwd`
-n #按照数值排序du -hs * | sort -nr
-r #反向排序 4.3.2 grep - 搜索文件
-i # 忽略大小写
-c # 只输出匹配行的数量
-l # 只列出符合匹配的文件名,不列出具体的匹配行
-n # 列出所有的匹配行,显示行号
-h # 查询多文件时不显示文件名
-s # 不显示不存在、没有匹配文本的错误信息
-v # 显示不包含匹配文本的所有行
-w # 匹配整词
-x # 匹配整行
-r # 递归搜索
-q # 禁止输出任何结果,已退出状态表示搜索是否成功
-b # 打印匹配行距文件头部的偏移量,以字节为单位
-o # 与-b结合使用,打印匹配的词据文件头部的偏移量,以字节为单位
-F # 匹配固定字符串的内容
-E # 支持扩展的正则表达式
grep [tf] file1 #支持正则匹配egrep, fgrep 功能更强大
4.3.3 zip , gzip:gz, compress:Z, bzip2:bz2 压缩数据
gzip #压缩文件
gzcat #查看文件内容
gunzip #用来解压文件 4.3.4 tar 归档数据
-c #~ create`创建一个新的tar文件
-r #追加文件到tar文件末尾
-x #~ extract`抽取tar文件
-v #显示文件列表
-z #将输出重定向给gzip命令
-f # file`输出文件结果到文化,`tar -cvf test.tar test/ test2/` 创建一个新文件
-t # list`列举tar内容
-C #指定具体目录
tar -xvf test.tar`令从tar文件test.tar中提取内容。如果tar文件是从一个目录结构创建的,那整个目录结构都会在当前目录下重新创建4.3.5 find 搜索命令
语法结构: find [路径] [参数]
-name # 匹配名称
-perm # 匹配权限(mode为完全匹配,-mode为包含即可)
-user # 匹配所有者
-group # 匹配所有组
-mtime -n +n # 匹配修改内容的时间(-n指n天以内,+n指n天以前)
-atime -n +n # 匹配访问文件的时间(-n指n天以内,+n指n天以前)
-ctime -n +n # 匹配修改文件权限的时间(-n指n天以内,+n指n天以前)
-nouser # 匹配无所有者的文件
-nogroup # 匹配无所有组的文件
-newer f1 !f2 # 匹配比文件f1新但比f2旧的文件
-type b/d/c/p/l/f # 匹配文件类型(后面的字幕字母依次表示块设备、目录、字符设备、管道、链接文件、文本文件)
-size # 匹配文件的大小(+50KB为查找超过50KB的文件,而-50KB为查找小于50KB的文件)
-prune # 忽略某个目录
-exec …… {}\; # 后面可跟用于进一步处理搜索结果的命令具体实例
# 搜索文件大于1M大小的文件
find /etc -size +1M
# 搜索所有属于指定用户的文件
find /home -user linuxprobe
# 在/var/log目录下搜索所有指定后缀的文件,后缀不需要大小写。
find /var/log -iname "*.log"
# 在/var/log目录下搜索所有后缀不是.log的文件:
find /var/log ! -name "*.log"
# 全盘搜索系统中所有类型为目录,且权限为1777的目录文件
find / -type d -perm 1777
#全盘搜索系统中所有后缀为.mp4的文件,并删除所有查找到的文件:
find / -name "*.mp4" -exec rm -rf {} \;4.3.6 uname 显示系统内核信息
语法格式:uname [参数]
常用参数
-a # 显示系统所有相关信息
-m # 显示计算机硬件架构
-n # 显示主机名称
-r # 显示内核发行版本号
-s # 显示内核名称
-v # 显示内核版本
-p # 显示主机处理器类型
-o # 显示操作系统名称
-i # 显示硬件平台4.4 date命令及其格式化
格式化占位符
%D – Display date as mm/dd/yy %Y – Year (e.g., 2020) %m – Month (01-12) %B – Long month name (e.g., November) %b – Short month name (e.g., Nov) %d – Day of month (e.g., 01) %j – Day of year (001-366) %u – Day of week (1-7) %A – Full weekday name (e.g., Friday) %a – Short weekday name (e.g., Fri) %H – Hour (00-23) %I – Hour (01-12) %M – Minute (00-59) %S – Second (00-60)date时间加减
echo `date --date="-5 day" +%Y%m%d` echo `date --date="-5 month" +%Y%m%d` echo `date --date="-5 year" +%Y%m%d`set和change系统时间
date --set="20100513 05:30"谨慎使用展示某一日期文件的日期
--file选项打印出文件中每一行存在的日期字符串。date --file=重写日期
date -d 'TZ="Australia/Sydney" 04:30 next Monday'下面命令可以列出
timezonetimedatectl list-timezones与其他shell混用
mysqldump database_name > database_name-$(date +%Y%m%d).sql使用Unix纪元时间(纪元转换)。
date +%s # To show the number of seconds from the epoch to the current day, use the %s format control date -d "1984-04-08" +"%s" # To see how many seconds passed from epoch to a specific date, enter
一个完整的带有详细时间的date命令是date --date="-5 day" +"%Y-%m-%d %H:%M:%S"
5. 理解shell
5.1 shell的类型
不同Linux系统有很多种shell,cat /etc/passwd可以看到用户默认登录默认的shell
- Debian的是dash
- csh
- sh(你经常会看到某些发行版使用软链接将默认的系统shell设置成bash shell,如本书所使用的CentOS发行版)
5.2 shell的父子关系
在生成子shell进程时,只有部分父进程的环境被复制到子shell环境中的一些东西造成影响
| 参数 | 描述 |
|---|---|
| -c string | 从 string 中读取命令并进行处理 |
| -i | 启动一个能够接收用户输入的交互shell |
| -l | 以登录shell的形式启动 |
| -r | 启动一个受限shell,用户会被限制在默认目录中 |
| -s | 从标准输入中读取命令 |
5.2.1 进程列表
(pwd ; ls ; cd /etc ; pwd ; cd ; pwd ; ls),括号的加入使命令列表变成了进程列表,生成了一个子shell来执行对应的命令- 语法为
{ command; }。使用花括号进行命令分组,并不会像进程列表那样创建出子shell - ( pwd ; (echo $BASH_SUBSHELL)) 创建子shell的子shell
- 在shell脚本中,经常使用子shell进行多进程处理。但是采用子shell的成本不菲,会明显拖慢
处理速度。在交互式的CLI shell会话中,子shell同样存在问题。它并非真正的多进程处理,因为
终端控制着子shell的I/O
5.2.2 子shell的其他用法
- 后台运行模式( & )
- 进程列表置于后台 (sleep 2 ; echo $BASH_SUBSHELL ; sleep 2) &
- 携程
- coproc My_Job { sleep 10; }, My_Job 是自定义名字,必须确保在第一个花括号( { )和命令名之间有一个空格
- 将
协程与进程列表结合起来产生嵌套的子shell。只需要输入进程列表,
然后把命令coproc放在前面就行了coproc ( sleep 10; sleep 2 )
5.3 理解shell的内建命令
5.3.1 外部命令
当外部命令执行时,会创建出一个子进程。这种操作被称为衍生(forking),有时候也被称为文件系统命令,是存在于bash shell之外的程序。它们并不是shell程序的一部分。外部命令程序通常位于/bin、/usr/bin、/sbin或/usr/sbin中
which pstype -a ps- 当进程必须执行衍生操作时,它需要花费时间和精力来设置新子进程的环境。所以说,外部命令多少还是有代价的,就算衍生出子进程或是创建了子shell,你仍然可以通过发送信号与其沟通,这一点无论是
在命令行还是在脚本编写中都是极其有用的
5.3.2 内部命令
- 命令
type -a显示出了每个命令的两种实现。注意, which 命令只显示出了外部命令文件 !数字可以使用.bash_history文件的命令alias -p,有一个别名取代了标准命令ls.它自动加入了--color选项,表明终端支持彩色模式的列表alias li='ls -li',一个别名仅在它所被定义的shell进程中才有效
6. 环境变量
- login shell : 用户成功登陆后使用的是 Login shell。例如,当你通过终端、SSH 或使用 “su -“ 命令来切换账号时都会使用的Login Shell
- non-login shell : Non Login Shell 是指通过 login shell 开启的shell,Non-login shell执行
~/.bashrc脚本来初始shell环境 - 交互式shell : 就是终端等待你输入命令的就是交互式shell
- 非交互式shell : 非交互式模式,以shell script(非交互)方式执行。在这种模式 下,shell不与你进行交互,而是读取存放在文件中的命令,并且执行它们。当它读到文件的结尾EOF,shell也就终止了
如何快速辨别是login shell 还是non-login shell ,可通过echo $0如果是输出-bash说明是login shell,bash说明是non-login shell
全局环境变量对于所有shell都是可见的,对于子shell来说这是非常重要的,
printenvorenv命令查看全局命令局部变量,
set返回全局变量,用户自定义变量,所以返回局部变量有点复杂,以字母序进行排序用户自定义变量
echo $my_variable -> my_variable=Hello可赋值,并且当你想要使用自定义变量时候要使用${my_variable}语法,大小写敏感设置全局环境变量
export my_variable导出为全局变量,在子shell中修改该值,只会在子shell中生效unset my_variable删除环境变量,这条规则的一个例外就是使用 printenv 显示某个变量的值)默认的环境变量,直接使用就好了


设置
path环境变量,当你在shell命令行界面中输入一个外部命令时,shell必须搜索系统来找到对应的程序.PATH环境变量定义了用于进行命令和程序查找的目录定位环境变量
- 登录式shell
在你登入Linux系统启动一个bash shell时,默认情况下bash会在几个文件中查找命令。这些文件叫作启动文件或环境文件。bash检查启动文件的方式取决于你启动bash的方式,启动bash shell有3种方式登录时作为默认登录shell(login shell)
当你登录系统的时候,bash shell会作为登陆式shell进行启动,会在如下文件五个不同启动文件读取命令/etc/profile,$HOME/.bash_profile,$HOME/.bash_login,$HOME/.profile,$HOME/.bashrc/etc/profile是系统默认的bash shell主启动文件,系统上每个用户登陆时候都会读取这个主启动文件,
两个发行版的/etc/profile文件都用到了同一个特性:for语句。它用来迭代/etc/profile.d目录,这为Linux系统提供了一个放置特定应用程序启动文件的地方,
当用户登录时,shell会执行这些文件。在本书所用的Ubuntu Linux系统中,/etc/profile.d目录下包含以下文件- shell会按照按照下列顺序,运行第一个被找到的文件,余下的则被忽略,这里没提到
$HOME/.bashrc文件,这个文件通常是通过其他文件运行$HOME/.bash_profile$HOME/.bash_login$HOME/.profile
NOTE : 要留意的是有些Linux发行版使用了可拆卸式认证模块(Pluggable AuthenticationModules ,PAM)。在这种情况下,PAM文件会在bash shell启动之前处理,这些文件中可能会包含环境变量。PAM文件包括
/etc/environment文 件 和$HOME/.pam_environment文件
- 交互式shell(non-login shell)
如果你的shell不是登录系统时候启动的,那么你启动的shell就是交互式shell,它不会访问/etc/profile只会检查.bashrc文件,.bashrc文件有两个作用:一是查看/etc目录下通用的bashrc文件,二是为用户提供一个定制自己的命令别名(参见第5章)和私有脚本函数的地方(将在第17章中讲到) - 非交互shell
TBC - 环境变量的持久化
对全局环境变量来说(Linux系统中所有用户都需要使用的变量),可能更倾向于将新的或修改过的变量设置放在/etc/profile文件中,但这可不是什么好主意。如果你升级了所用的发行版,这个文件也会跟着更新,那你所有定制过的变量设置可就都没有了。最好是在/etc/profile.d目录中创建一个以.sh结尾的文件。把所有新的或修改过的全局环境变量设置放在这个文件中。在大多数发行版中,存储个人用户永久性bash shell变量的地方是$HOME/.bashrc文件。这一点适用于所有类型的shell进程。但如果设置了BASH_ENV变量,那么记住,除非它指向的是$HOME/.bashrc,否则你应该将非交互式shell的用户变量放在别的地方
- 登录式shell
环境变量数组
mytest=(one two three four five)定义了环境变量数组,echo ${mytest[2]}使用下标索引可以访问具体值,echo ${mytest[*]}可以访问所有的值,unset mytest[2]删除某个值,unset mytest删除全部总结
bash shell会在启动时执行几个启动文件。这些启动文件包含了环境变量的定义,可用于为每个bash会话设置标准环境变量。每次登录Linux系统,bash shell都会访问/etc/profile启动文件以及3个针对每个用户的本地启动文件:$HOME/.bash_profile、$HOME/.bash_login和$HOME/.profile。用户可以在这些文件中定制自己想要的环境变量和启动脚本。
7. linux文件权限
用户权限是通过创建用户时分配的用户ID(User ID,通常缩写为UID)来跟踪的。UID是数值,每个用户都有唯一的UID,但在登录系统时用的不是UID,而是登录名。登录名是用户用来登录系统的最长八字符的字符串(字符可以是数字或字母),同时会关联一个对应的密码
7.1 linux的安全性
7.1.1 /etc/passwd文件
/etc/passwd包含用户的基本信息,所有在服务器后台运行都需要个系统账户运行
1. 登录用户名
2. 用户密码
3. 用户账户的UID(数字形式)
4. 用户账户的组ID(GID)(数字形式)
5. 用户账户的文本描述(称为备注字段)
6. 用户HOME目录的位置
7. 用户的默认shell root固定分配UID是0,Linux系统会为各种各样的功能创建不同的用户账户,而这些账户并不是真的用户。这些账户叫作系统账户,是系统上运行的各种服务进程访问资源用的特殊账户。所有运行在后台的服务都需要用一个(application account),如果全都是root权限登录系统就很危险,被攻陷就直接是root权限。
大多数创建的用户都是会在500开始,500以上是给特定的程序使用
7.1.2 /etc/shadow文件
/etc/shadow真正存密码的文件,只允许root用户访问1. 与/etc/passwd文件中的登录名字段对应的登录名 2. 加密后的密码 3. 自上次修改密码后过去的天数密码(自1970年1月1日开始计算) 4. 多少天后才能更改密码 5. 多少天后必须更改密码 6. 密码过期前提前多少天提醒用户更改密码 7. 密码过期后多少天禁用用户账户 8. 用户账户被禁用的日期(用自1970年1月1日到当天的天数表示) 9. 预留字段给将来使用
7.1.3 添加linux新用户
useradd命令添加默认配置的用户,/etc/default/useradd可以加入-D选项查看默认参数如下(一些Linux发行版会把Linux用户和组工具放在/usr/sbin目录下,这个目录可能不在PATH环境变量里)- 新用户会被添加到GID为100 的公共组;
- 新用户的HOME目录将会位于/home/loginname;
- 新用户账户密码在过期后不会被禁用;
- 新用户账户未被设置过期日期;
- 新用户账户将bash shell作为默认shell;
- 系统会将/etc/skel目录下的内容复制到用户的HOME目录下;
- 系统为该用户账户在mail目录下创建一个用于接收邮件的文件
/etc/skel下面它们是bash shell环境的标准启动文件,允许管理员把它作为创建新用户HOME目录的模板。这样就能自动在每个新用户的HOME目录里放置默认的系统文件,useradd参数可以控制这些默认值,ubuntu系统在/etc/skel下,useradd默认命令行参数-c comment 给新用户添加备注 -d home_dir 为主目录指定一个名字(如果不想用登录名作为主目录名的话) -e expire_date 用YYYY-MM-DD格式指定一个账户过期的日期 -f inactive_days 指定这个账户密码过期后多少天这个账户被禁用;0表示密码一过期就立即禁用,1表示禁用这个功能 -g initial_group 指定用户登录组的GID或组名 -G group ... 指定用户除登录组之外所属的一个或多个附加组 -k 必须和-m一起使用,将/etc/skel目录的内容复制到用户的HOME目录 -m 创建用户的HOME目录 -M 不创建用户的HOME目录(当默认设置里要求创建时才使用这个选项) -n 创建一个与用户登录名同名的新组 -r 创建系统账户 -p passwd 为用户账户指定默认密码 -s shell 指定默认的登录shell -u uid 为账户指定唯一的UID同时也可以更改默认值的参数
-b default_home 更改默认的创建用户HOME目录的位置 -e expiration_date 更改默认的新账户的过期日期 -f inactive 更改默认的新用户从密码过期到账户被禁用的天数 -g group 更改默认的组名称或GID -s shell 更改默认的登录shell # 更改用户默认shell useradd -D -s /bin/tsch
7.1.4 删除用户
/user/sbin/userdel只是删除/etc/passwd上面的信息,而不会删除任何系统上的文件,但是-r参数就会删除用户目录下的所有的文件
7.1.5 修改用户
Linux提供了一些不同的工具来修改已有用户账户的信息
usermod 修改用户账户的字段,还可以指定主要组以及附加组的所属关系
passwd 修改已有用户的密码
chpasswd 从文件中读取登录名密码对,并更新密码
chage 修改密码的过期日期
chfn 修改用户账户的备注信息
chsh 修改用户账户的默认登录shell usermodusermod命令是用户账户修改工具中最强大的一个。它能用来修改/etc/passwd文件中的大部分字段,只需用与想修改的字段对应的命令行参数就可以了。参数大部分跟useradd命令的参数一样(比如,-c修改备注字段,-e修改过期日期,-g修改默认的登录组)。除此之外,还有另外一些可能派上用场的选项。要让账户恢复正常,只要用-U选项就行了。 -l修改用户账户的登录名。 -L锁定账户,使用户无法登录。 -p修改账户的密码。 -U解除锁定,使用户能够登录。 -L选项尤其实用。它可以将账户锁定,使用户无法登录,同时无需删除账户和用户的数据。usermod -l login-name old-name- passwd和chpasswd,如果只用passwd命令,它会改你自己的密码。系统上的任何用户都能改自己的密码,但只有root用户才有权限改别人的密码。-e选项能强制用户下次登录时修改密码。你可以先给用户设置一个简单的密码,之后再强制在下次登录时改成他们能记住的更复杂的密码。如果需要为系统中的大量用户修改密码,chpasswd命令可以事半功倍。chpasswd命令能从
标准输入自动读取登录名和密码对(由冒号分割)列表,给密码加密,然后为用户账户设置。你也可以用重定向命令来将含有userid:passwd对的文件重定向给该命令。# passwd test Changing password for user test. New UNIX password: Retype new UNIX password: passwd: all authentication tokens updated successfully.# chpasswd < users.txt - chsh、chfn和chage
chsh、chfn和chage工具专门用来修改特定的账户信息。chsh命令用来快速修改默认的用户登录shell。使用时必须用shell的全路径名作为参数,不能只用shell名。
chfn命令提供了在/etc/passwd文件的备注字段中存储信息的标准方法。chfn命令会将用于Unix的finger命令的信息存进备注字段,而不是简单地存入一些随机文本(比如名字或昵称之类的),或是将备注字段留空。finger命令可以非常方便地查看Linux系统上的用户信息。# chsh -s /bin/csh test Changing shell for test. Shell changed.
如果在使用chfn命令时没有参数,它会向你询问要将哪些适合的内容加进备注字段。# finger rich Login: rich Name: Rich Blum Directory: /home/rich Shell: /bin/bash On since Thu Sep 20 18:03 (EDT) on pts/0 from 192.168.1.2 No mail. No Plan.
所有的指纹信息现在都存在/etc/passwd文件中了。最后,chage命令用来帮助管理用户账户的有效期。你需要对每个值设置多个参数,如表7-4所示。# chfn test Changing finger information for test. Name []: Ima Test Office []: Director of Technology Office Phone []: (123)555-1234 Home Phone []: (123)555-9876
chage命令的日期值可以用下面两种方式中的任意一种: YYYY-MM-DD格式的日期 代表从1970年1月1日起到该日期天数的数值chage命令中有个好用的功能是设置账户的过期日期。有了它,你就能创建在特定日期自动过期的临时用户,再也不需要记住删除用户了!过期的账户跟锁定的账户很相似:账户仍然存在,但用户无法用它登录。参 数 描 述 -d 设置上次修改密码到现在的天数 -E 设置密码过期的日期 -I 设置密码过期到锁定账户的天数 -m 设置修改密码之间最少要多少天 -W 设置密码过期前多久开始出现提醒信息
7.2 使用linux组
7.2.1 /etc/group文件
/etc/group存储一个组的信息,低于500是系统的,高于500是用户组的- 组名
- 组密码
- GID
- 属于该组的用户列表
/etc/passwd中指定了默认组之后就不会再/etc/group就不会在对应组后面显示用户名
7.2.2 创建新的组
/user/sbin/groupadd 创建新的组,要注意-g和-G的区别
/user/sbin/groupmod -G shared rich 修改组并添加用户
7.3 理解文件权限
7.3.1 使用文件权限符
如果你还记得第3章,那应该知道ls命令可以用来查看Linux系统上的文件、目录和设备的权限。输出结果的第一个字段就是描述文件和目录权限的编码,文件权限符号:
`-`代表文件
`d` 代表目录
`l` 代表链接
`c` 代表字符型设备
`b` 代表块设备
`n` 代表网络设备
接下来三个是文件owner,和对象组
`r` 可写
`w` 可写
`x` 可执行若没有某种权限,在该权限位会出现单破折线,对象(文件/目录)的属主,对象的属组,系统其他用户
7.3.2 默认文件权限
创建一个文件时候所赋予的默认权限是通过umask控制,执行unask会输出四位数,第一位代表了一项特别的安全特性,叫作粘着位(sticky bit)
后面的3位表示文件或目录对应的umask八进制值。要理解umask是怎么工作的,得先理解八进制模式的安全性设置。
八进制模式的安全性设置先获取这3个rwx权限的值,然后将其转换成3位二进制值,用一个八进制值来表示。在这个二进制表示中,每个位置代表一个二进制位。因此,如果读权限是唯一置位的权限,权限值就是r–,转换成二进制值就是100,代表的八进制值是4。表7-5列出了可能会遇到的组合。
权 限 二进制值 八进制值 描 述
--- 000 0 没有任何权限
--x 001 1 只有执行权限
-w- 010 2 只有写入权限
-wx 011 3 有写入和执行权限
r-- 100 4 只有读取权限
r-x 101 5 有读取和执行权限
rw- 110 6 有读取和写入权限
rwx 111 7 有全部权限八进制模式先取得权限的八进制值,然后再把这三组安全级别(属主、属组和其他用户)的八进制值顺序列出。因此,八进制模式的值664代表属主和属组成员都有读取和写入的权限,而其他用户都只有读取权限
umask值反而更叫人困惑了。我的Linux系统上默认的八进制的umask值是0022,而我所创建的文件的八进制权限却是644,这是如何得来的呢?
对文件来说,全权限的值是666(所有用户都有读和写的权限);而对目录来说,则是777
所以在上例中,文件一开始的权限是666,减去umask值022之后,剩下的文件权限就成了644
所以在上例中,目录一开始的权限是777,减去umask值022之后,剩下的文件权限就成了744
在大多数Linux发行版中,umask值通常会设置在/etc/profile启动文件中(参见第6章),不过有一些是设置在/etc/login.defs文件中的(如Ubuntu)。可以用umask命令为默认umask设置指定一个新值。
umask 026 7.4 改变安全性设置
7.4.1 改变文件权限
chmod 改文件权限,如果使用的符号模式设置就是
u代表用户,g代表组,o代表其他,a代表所有,+代表增加权限,-代表移除权限,=将权限设置成后面的值,额外的第三作用符号如下`X` :如果对象是目录或者它已有执行权限,赋予执行权限。 `s` :运行时重新设置UID或GID。 `t` :保留文件或目录。 `u` :将权限设置为跟属主一样。 `g` :将权限设置为跟属组一样。 `o` :将权限设置为跟其他用户一样
7.4.2 改变文件所属关系
- chown 改文件所属
chown option owner file[.group] filechown owner.group file直接改属主和组chown owner .属主和组都同名chgrp更改文件目录的默认属组
7.5 共享文件
Linux还为每个文件和目录存储了3个额外的信息位。
- 设置用户ID(SUID):当文件被用户使用时,程序会以文件属主的权限运行。
- 设置组ID(SGID):对文件来说,程序会以文件属组的权限运行;对目录来说,目录中创建的新文件会以目录的默认属组作为默认属组。
- 粘着位:进程结束后文件还驻留(粘着)在内存中。
如果你用的是八进制模式,你需要知道这些位的位置
| 二进制值 | 八进制值 | 描述 |
|---|---|---|
| 000 | 0 | 所有位都清零 |
| 001 | 1 | 粘着位置位 |
| 010 | 2 | SGID位置位 |
| 011 | 3 | SGID位和粘着位都置位 |
| 100 | 4 | SUID位置位 |
| 101 | 5 | SUID位和粘着位都置位 |
| 110 | 6 | SUID位和SGID位都置位 |
| 111 | 7 | 所有位都置位 |
首先,用 mkdir 命令来创建希望共享的目录。然后通过 chgrp 命令将目录的默认属组改为包
含所有需要共享文件的用户的组(你必须是该组的成员)。最后,将目录的SGID位置位,以保证
目录中新建文件都用shared作为默认属组
$ mkdir testdir
$ ls -l
drwxrwxr-x 2 rich rich 4096 Sep 20 23:12 testdir/
$ chgrp shared testdir
$ chmod g+s testdir // chmod 6770 testdir
$ ls -l
drwxrwsr-x 2 rich shared 4096 Sep 20 23:12 testdir/
$ umask 002
$ cd testdir
$ touch testfile
$ ls -l
total 0
-rw-rw-r-- 1 rich shared 0 Sep 20 23:13 testfile
8.管理文件系统
用Linux系统时,需要作出的决策之一就是为存储设备选用什么文件系统。大多数Linux发行版在安装时会非常贴心地提供默认的文件系统,大多数入门级用户想都不想就用了默认的那个
9. 安装软件程序
9.1 包管理工具
管理版本
9.2 基于Debian的系统
基于 Debian 的系统
- dpkg 包管理工具
- apt
- apt-get
- aptitude
9.2.1 用aptitude 管理软件包
apt,dpkg是包管理工具,aptitude是完整的软件包管理系统
- aptitude show wine 显示包wine的详细信息
- aptitude install package_name
- aptitude search package_name
如果看到一个i,说明这个包现在已经安装到了你的系统上了。如果看到一个p或v,说明这个包可用,但还没安装 - aptitude safe-upgrade
- aptitude remove/purge package_name
/etc/apt/sources.list前面有deb说明是编译过的,deb-src是源代码,package_type_list 条目可能并不止一个词,它还表明仓库里面有什么类型的包。你可以看到诸如main、restricted、universe和partner这样的值
dpkg -L vim 显示vim的所有安装信息
dpkg –search vim
9.3 基于源码安装
C++编译要使用CMake
10. 使用编辑器
10.1 vim 编辑器
移动光标
文件很大,用方向键移动 gg 移动到最后一行 num G 移动到指定行数 G 移动到第一行 w file_name 将文件保存到另一个文件中 Pagedown + Pageup 翻页 w file_name 保存为另一个文件编辑数据
x 删除光标当前所在字符(剪切) dd 是切除当前行, p 是粘贴(剪切) dw 删除光标当前所在当前字符(剪切) yw 复制一个单词 y$复制整个行 u 撤销 a 在文件尾追加数据 A 在当前行尾追加数据 r char 用char 替换当前光标位置字符 R char 用text文本替换当前文本字符替换数据
:s/old/new/ 替换数据 :s/olr/new/g 替换文件中一行所有old :m,ns/old/new/g 替换行号之间的所有old :$s/old/new/g 替换整个文件中的old :$s/old/new/gc 替换整个文件中的old,但是每次都提醒
11.基本脚本
创建shell脚本
#!/bin/bash,bash找你的文件都是从path目录下,如果没有设置path目录那么就需要通过绝对路径和相对路径引用你的命令。然后是注意你的文件权限umask决定了你文件创建时候的默认权限文本信息
echo可使用单引号和双引号来划定文本字符串echo "This is a test to see if you're paying attention"文本中有单引号echo 'Rich says "scripting is easy".'文本中有双引号- 如果是单/双引号混合会怎样?
- 文本字符串和命令输出到同一行
使用变量
- 用户变量区分大小写长度不超过20个字符
- 变量,等号,值之间不能出现空格
- 引用一个变量值时需要使用美元符,而引用变量来对其进行赋值时则不要使用美元符.没有美元符号引用变量进行赋值shell就会将其理解为字符串
- 命令替换分为
$()和` `,testing=$(date)他们中间没有空格.命令替换会创建一个子shell来运行对应的命令。子shell(subshell)是由运行该脚本的shell所创建出来的一个独立的子shell(child shell)。正因如此,由该子shell所执行命令是无法使用脚本中所创建的变量的.在命令行提示符下使用路径./运行命令的话,也会创建出子shell;要是运行命令的时候不加入路径,就不会创建子shell。如果你使用的是内建的shell命令,并不会涉及子shell。在命令行提示符下运行脚本时一定要留心!
输入输出重定向
>会覆盖,>>追加wc < test6输入重定向,内联重定向<<,在命令行上使用内联输入重定向时,shell会用PS2环境变量中定义的次提示符(参见第6章)- 管道,Linux管道命令(断条符号)允许你将命令的输出直接重定向到另一个命令的输入。【这里的问题还很多】
执行数学计算
expr命令,特别注意expr 1+5这种是不起作用的(建议以后少用)$[ ]对expr的改进,bash shell数学运算符只支持整数运算,zsh支持浮点运算bc计算器scale=4保留四位精度,3.44 / 5 = .6880, 支持定义变量在脚本中使用
bc,variable=$(echo "scale=4 ;3.44 / 5" | bc),var3=$(echo "scale=4; $var1 / $var2" | bc)这里的var1和var2都是预定义的将表达式定义到一个文件中,或者内联表达式
#!/bin/bash var1=10.46 var2=43.67 var3=33.2 var4=71 var5=$(bc << EOF scale = 4 a1 = ( $var1 * $var2) b1 = ($var3 * $var4) a1 + b1 EOF ) echo The final answer for this mess is $var5
退出脚本
0成功结束,1一般未知错误,2不适合的shell命令,126命令不可执行,127没找到命令,128无效退出参数,128+x与linux信号x相关的严重错误,130通过ctrl+退出,255正常范围之外的退出状态码exit退出命令,可以自定义状态码,退出状态码最大只能是255,所以超过255会进行模运算
12. 使用结构化命令
if statement
## style 1 if pwd then echo "it works" fi ## style 2 if [ pwd ] ; then echo "it works" fi # style 3 ## 如果grep返回0 就去执行echo statement if grep $testuser /etc/passwd then echo "this is my first command" echo "this is my second command" fi ## if elif else ,在elif语句中,紧跟其后的else语句属于elif代码块。它们并不属于之前的if-then代码块 if pwd then echo 1 else | elif command ;then echo 3 ; else fi echo 2 fitest命令
如果test命令中列出的条件成立,test命令就会退出并返回退出状态码0。这样if-then语句就与其他编程语言中的if-then语句以类似的方式工作了。如果条件不成立,test命令就会退出并返回非零的退出状态码,这使得if-then语句不会再被执行。支持符合条件检查
## 单一逻辑校验 if [ condition ] then commands fi ## 符合逻辑校验 if [ condition1 ] && [ condition2 ] || [ condition ] then commands fi数值比较
- n1 -eq n2 等于
- n1 -ge n2 大于等于
- n1 -gt n2 大于
- n1 -le n2 小于等于
- n1 -lt n2 小于
- n1 -ne n2 不等于
字符串比较
- str1 = str2 字面量相等,在比较字符串的相等性时,比较测试会将所有的标点和大小写情况都考虑在内
- str1 != str2 不相等
- str1 < str2 小于.
if [ $val1 > $val2 ]直接这样比较字符串会创建一个文件。所以必须要转义if [ $val1 \> $val2 ]。在比较测试中,大写字母被认为是小于小写字母的。比较测试中使用的是标准的ASCII顺序,根据每个字符的ASCII数值来决定排序结果但sort命令恰好相反,本地语言设置(英语),A在a前面 - str1 > str2 大于
- -n str1 判断长度是否为非零
- -z str1 判断长度是否为零
文件比较
比较 描述 -d file d=directory. 检查file是否存在并是一个目录 -e file e=exist. 检查file是否存在 -f file f=file. 检查file是否存在并是一个文件 -r file r=read. 检查file是否存在并可读 -s file s=检查file 是否存在并非空 -w file w=write. 检查file是否存在并可写 -x file 检查file 是否存在并可执行 -O file O=all user 检查file是否存在并属当前用户所有 -G file G=group 检查file是否存在并且默认组与当前用户相同 file1 -nt file2 检查file1是否比file2新 file1 -ot file2 检查file1是否比file2旧
(( ))和[[ ]]提供高级特性
- (( )) 提供更加方便的数学表达式计算,像其他oop语言一样
- [[ ]] 提供更加方便的字符串处理功能
case命令case variable in pattern1 | pattern2 ) command1;; pattern3) command2;; *) command3;; esac
summary:
- [ ‘var1’ = ‘var2’ ] 等待前后留一个空格,然后与两端也要留空格.
[ $val1 > $val2 ]直接这样比较字符串会创建一个文件- linux中的字符串是双引号的
13. for 循环
13.1 for命令
- for 基本语句
list="Alabama Alaska Arizona Arkansas Colorado"
list=$list" Connecticut"
for v in v_list
do
echo 1
done
v_list如果有单引号,1.用转义字符转义。2.用双引号定义用到的单引号的值。3.如果在单独的数据值中有空格,就必须用双引号将这些值圈起来,可直接拼接值。
file="path of your file"
for state in $(cat $file)
do
echo "Visit beautiful $state"
done
读取文件内容进行迭代
(ubuntu没有IFS环境变量和IFS.OLD)
更改字段分隔符
默认分隔符是空格,制表符,换行符环境变量IFS,控制着字段分隔符,有时候想灵活一点,有些地方用的换行符,但是其他地方继续保留原先的分隔符,可使用IFS=$’\n’, IFS.OLD=$IFS,IFS=$’\n’,但是如果想加入冒号作为换行符可以更改/etc/passwd文件加上IFS=:,如果想加多个可以依次在后面加IFS=’\n’:;”通配符
#!bin/bash for file in /home/rich/test/* do if [ -d "$file" ] then echo "$file is a directory" elif [ -f "$file" ] then echo "$file is a file" fi done ## 目录文件都会匹配 ##请注意这次条件判断有些特别使用了if [ -d "$file" ] 因为在linux中文件名有空格是合法的
13.2 C语言风格
for (( a=1,b=10;a<=10;a++,b--))
do
echo 1
done
13.3 while语句
while true
do
echo
done
break 还可以指定跳出循环层数,两层for就跳出最内层,break n就会跳出.continue结束本次循环,n为1,表明跳出的是当前的循环。如果你将n设为2,break命令就会停止下一级的外部循环
处理循环中的输出
for file in /home/rich/* do if [ -d "$file" ] then echo "$file is a directory" elif echo "$file is a file" fi done > output.txt处理多个测试命令
这种情况下要注意,判断了所有条件,因为有一个条件返回为false,所以相当于逻辑
与判断#!/bin/bash # testing a multicommand while loop var1=10 while echo $var1 [ $var1 -ge 0 ] do echo "This is inside the loop" var1=$[ $var1 - 1 ] done
while 或者for的嵌套循环中,内部循环可以读到外部变量
13.4 until命令
有点像其他语言的
do …. while 语法
13.5 循环处理数据并以特定分隔符分割数据
主要是修改IFS变量
#!/bin/bash
# changing the IFS value
IFS.OLD=$IFS
IFS='\n'
for entry in $(cat /etc/passwd)
do
echo "Values in $entry –"
IFS=':'
for value in $entry
do
echo " $value"
done
done 14. 处理用户输入
14.1 读取参数,脚本名和测试参数
./sumAB.sh a b ## 这里$0是程序名,
$1是a,$2是b. 超过九个就一定要花括号引用变量比如${10},$#返回参数个数,${!#}获取最后一个参数,如果没有参数就会输出脚本名,$*变量会将所有参数当成单个参数,$@变量会组成数组,轻松访问所有的参数.for param in "$@" do echo "\$@ Parameter #$count = $param" count=$[ $count + 1 ] done如果程序名是
./test.sh,那么echo $0 就是./test.sh如果程序名是
bash /usr/lib/test.sh,那么echo $0 就是/usr/lib/test.sh定义了参数位置,如果不传参会报错
name=$(basename $0)可以只返回脚本名if [ -n "$1" ]是指$1不为空shift命令会移动命令参数,shift n可以指定跳过n参数.
14.2 处理选项
bash命令提供了选项和参数来控制,可以通过shift命令来控制
处理简单的选项
#!/bin/bash # extracting command line options as parameters # echo while [ -n "$1" ] do case "$1" in -a) echo "Found the -a option" ;; -b) echo "Found the -b option" ;; -c) echo "Found the -c option" ;; *) echo "$1 is not an option" ;; esac shift done $ ./test15.sh -a -b -c -d分离选项和参数
#!/bin/bash # extracting options and parameters echo while [ -n "$1" ] do case "$1" in -a) echo "Found the -a option" ;; -b) echo "Found the -b option";; -c) echo "Found the -c option" ;; --) shift break ;; *) echo "$1 is not an option";; esac shift done # count=1 for param in $@ do echo "Parameter #$count: $param" count=$[ $count + 1 ] done $ ./test16.sh -c -a -b -- test1 test2 test3处理带值的选项
#!/bin/bash # extracting command line options and values echo while [ -n "$1" ] do case "$1" in -a) echo "Found the -a option";; -b) param="$2" echo "Found the -b option, with parameter value $param" shift ;; -c) echo "Found the -c option";; --) shift break ;; *) echo "$1 is not an option";; esac shift done # count=1 for param in "$@" do echo "Parameter #$count: $param" count=$[ $count + 1 ] done $ ./test17.sh -a -b test1 -dcase语句定义了三个它要处理的选项。-b选项还需要一个额外的参数值。由于要处理的参数是$1,额外的参数值就应该位于$2(因为所有的参数在处理完之后都会被移出)。只要将参数值从$2变量中提取出来就可以了
使用getopt与getopts命令
getopts命令会用到两个环境变量。如果选项需要跟一个参数值,OPTARG环境变量就会保存这个值。
OPTIND环境变量保存了参数列表中getopts正在处理的参数位置。
这样你就能在处理完选项之后继续处理其他命令行参数了。#!/bin/bash # simple demonstration of the getopts command # echo while getopts :ab:c opt do case "$opt" in a) echo "Found the -a option" ;; b) echo "Found the -b option, with value $OPTARG";; c) echo "Found the -c option" ;; *) echo "Unknown option: $opt";; esac done $ bash ./test19.sh -a -b "1 2" -c # 在参数中加空格 $ bash ./test19.sh -abtest1 # 可以挨在一起 $ bash ./test19.sh -d # 返回问号 $ bash ./test19.sh -a -b 456 -cdefg# 如果有参数的就要分开写- 使用OPTIND参数和OPTARG参数
#!/bin/bash # Processing options & parameters with getopts # echo while getopts :ab:cd opt do case "$opt" in a) echo "Found the -a option" ;; b) echo "Found the -b option, with value $OPTARG" ;; c) echo "Found the -c option" ;; d) echo "Found the -d option" ;; *) echo "Unknown option: $opt" ;; esac done # shift $[ $OPTIND - 1 ] # echo count=1 for param in "$@" do echo "Parameter $count: $param" count=$[ $count + 1 ] done选项标准化
参数 解释 -a 显示所有对象 -c 生成一个计数 -d 指定一个目录 -e 扩展一个对象 -f 指定读入数据的文件 -h 显示命令的帮助信息 -i 忽略文本大小写 -l 产生输出的长格式版本 -n 使用非交互模式(批处理) -o 将所有输出重定向到的指定的输出文件 -q 以安静模式运行 -r 递归地处理目录和文件 -s 以安静模式运行 -v 生成详细输出 -x 排除某个对象 -y 对所有问题回答yes
14.3 获取用户输入
read命令,- read命令包含了-p选项,允许你直接在read命令行指定提示符,
- read命令会将提示符后输入的所有数据分配给单个变量,要么你就指定多个变量。输入的每个数据值都会分配给变量列表中的下一个变量。如果变量数量不够,剩下的数据就全部分配给最后一个变量
-t代表超时-n 1read命令来统计输入的字符数。当输入的字符达到预设的字符数时,就自动退出,将输入的数据赋给变量-s选项可以避免在read命令中输入的数据出现在显示器上- 从文件中读取数据
//单个变量 read -p "please enter your age" age //多个变量 read -p "please enter your name" first last // 超时参数 read -t 5 -p // 获取指定字符个数 read -n1 -p "Do you want to continue [Y/N]?" answer //隐藏输入 read -s -p "Enter your password: " pass // 从文件中读取数据 #!/bin/bash # reading data from a file # count=1 cat test | while read line do echo "Line $count: $line" count=$[ $count + 1] done echo "Finished processing the file"
15. 呈现数据
这一章主要是讲如何将脚本输出重定型向到系统其他位置
15.1 理解输入和输出
15.1.1 标准文件描述符
Linux系统将每个对象(操作的文件,linux万物皆文件)当作文件处理。这包括输入和输出进程。Linux用文件描述符(filedescriptor)来标识每个文件对象
文件描述符 缩 写 描 述
0 STDIN 标准输入
1 STDOUT 标准输出
2 STDERR 标准错误- STDIN实例
cat就会从STDIN输入数据,这时候你输入什么屏幕就会显示什么cat < file.txt通过STDIN通过重定向符号使cat查看一个非STDIN文件的输入 - STDOUT
- STDERR
shell通过特殊的STDERR文件描述符来处理错误消息。STDERR文件描述符代表shell的标准错误输出。shell或shell中运行的程序和脚本出错时生成的错误消息都会发送到这个位置
15.1.2 重定向错误
- 只重定向错误
通过2> file.txt的方式将错误信息重定向到文件中 - 重定向错误和数据
ls -al test test2 test3 badtest 2> test6 1> test7这种就是将STDERR重定向到test6,然后将STDOUT重定向到test7.
也可以将STDERR和STDOUT的输出重定向到同一个输出文件使用&>,比如ls -al test test2 test3 badtest &> test7,bash消息赋予error更高的优先级
15.2 在脚本中重定向输出
可以在脚本中用STDOUT和STDERR文件描述符以在多个位置生成输出,只要简单地重定向相应的文件描述符就行了。有两种方法来在脚本中重定向输出:
- 临时重定向行输出
- 永久重定向脚本中的所有命令
15.2.1 临时重定向
如果使用上文提到的STDERR重定向方法就会将全局的STDERR信息都重定向到文件中,但是如果只重定向自己特定某些error信息就可以使用临时重定向,必须在文件描述符数字之前加一个&
# 举个例子 ./test8
#!/bin/bash
# testing STDERR messages
echo "This is an error" >&2
echo "This is normal output" 临时重定向就是需要在脚本中一行一行的重定向log
如果像平常一样运行这个脚本,你可能看不出什么区别,因为所有输出都到了STDOUT,但是默认情况下,linux会将STDERR导向STDOUT,但是,如果你在运行脚本时重定向了STDERR,脚本中所有导向STDERR的文本都会被重定向。
$ ./test8 2> test9
This is normal output
$ cat test9
This is an error 15.2.2 永久重定向
脚本中有大量数据需要重定向,那重定向每个echo语句就会很烦琐。取而代之,你可以用exec命令告诉shell在脚本执行期间重定向某个特定文件描述符。
#!/bin/bash
# redirecting all output to a file
exec 1>testout
echo "This is a test of redirecting all output"
echo "from a script to another file."
echo "without having to redirect every individual line" 15.3 在脚本中重定向输入
exec命令允许你将STDIN重定向到Linux系统上的文件中exec 0< testfile
# redirecting file input
exec 0< testfile
count=1
while read line
do
echo "Line #$count: $line"
count=$[ $count + 1 ]
done 15.4 创建自己的重定向
15.4.1 创建输出文件描述符
可以用exec命令来给输出分配文件描述符。和标准的文件描述符一样,一旦将另一个文件
描述符分配给一个文件,这个重定向就会一直有效,直到你重新分配。这里有个在脚本中使用其
他文件描述符的简单例子。(不是太理解这句话)
#./test13
#!/bin/bash
# using an alternative file descriptor
exec 3>test13out
echo "This should display on the monitor"
echo "and this should be stored in the file" >&3
echo "Then this should be back on the monitor"
$ ./test13
This should display on the monitor
Then this should be back on the monitor
$ cat test13out
and this should be stored in the file
从表现上看,只有自己定义的重定向的输出会重定向到test13out文件。其他的还是会输出到STDOUT这个
脚本用exec命令将文件描述符3重定向到另一个文件。当脚本执行echo语句时,输出内容会像预想中那样
显示在STDOUT上。但你重定向到文件描述符3的那行echo语句的输出却进入了另一个文件。这样你就可以
在显示器上保持正常的输出,而将特定信息重定向到文件中(比如日志文件)。
15.4.2 重定向文件描述符
现在介绍怎么恢复已重定向的文件描述符。你可以分配另外一个文件描述符给标准文件描述
符,反之亦然。这意味着你可以将STDOUT的原来位置重定向到另一个文件描述符,然后再利用
该文件描述符重定向回STDOUT。听起来可能有点复杂,但实际上相当直接。这个简单的例子能
帮你理清楚。
# ./test14
#!/bin/bash
# storing STDOUT, then coming back to it
exec 3>&1
exec 1>test14out
echo "This should store in the output file"
echo "along with this line."
exec 1>&3
echo "Now things should be back to normal"
$
$ ./test14
Now things should be back to normal
$ cat test14out
This should store in the output file
along with this line.
$ 这个方法可能有点叫人困惑,但这是一种在脚本中临时重定向输出,然后恢复默认输出设置
的常用方法。
15.4.3 创建输入文件描述符
可以用和重定向输出文件描述符同样的办法重定向输入文件描述符。在重定向到文件之前,
先将STDIN文件描述符保存到另外一个文件描述符,然后在读取完文件之后再将STDIN恢复到它
原来的位置
#!/bin/bash
# redirecting input file descriptors
exec 6 < &0
exec 0< testfile
count=1
while read line
do
echo "Line #$count: $line"
count=$[ $count + 1 ]
done
exec 0<&6
read -p "Are you done now? " answer
case $answer in
Y|y) echo "Goodbye";;
N|n) echo "Sorry, this is the end.";;
esac
$ ./test15
Line #1: This is the first line.
Line #2: This is the second line.
Line #3: This is the third line.
Are you done now? y
Goodbye 15.4.4 创建读写文件描述符
(第一遍不是很懂)
尽管看起来可能会很奇怪,但是你也可以打开单个文件描述符来作为输入和输出。可以用同
一个文件描述符对同一个文件进行读写。
不过用这种方法时,你要特别小心。由于你是对同一个文件进行数据读写,shell会维护一个
内部指针,指明在文件中的当前位置。任何读或写都会从文件指针上次的位置开始。如果不够小
心,它会产生一些令人瞠目的结果。看看下面这个例子。
#!/bin/bash
# testing input/output file descriptor
exec 3<> testfile
read line <&3
echo "Read: $line"
echo "This is a test line" >&3
$ cat testfile
This is the first line.
This is the second line.
This is the third line.
#输出
$ ./test16
Read: This is the first line. 这个例子用了exec命令将文件描述符3分配给文件testfile以进行文件读写。接下来,它
通过分配好的文件描述符,使用read命令读取文件中的第一行,然后将这一行显示在STDOUT上。
最后,它用echo语句将一行数据写入由同一个文件描述符打开的文件中。
在运行脚本时,一开始还算正常。输出内容表明脚本读取了testfile文件中的第一行。但如果
你在脚本运行完毕后,查看testfile文件内容的话,你会发现写入文件中的数据覆盖了已有的数据。
当脚本向文件中写入数据时,它会从文件指针所处的位置开始。read命令读取了第一行数
据,所以它使得文件指针指向了第二行数据的第一个字符。在echo语句将数据输出到文件时,
它会将数据放在文件指针的当前位置,覆盖了该位置的已有数据。
15.4.5 关闭文件描述符
(第一遍不是很懂)
如果你创建了新的输入或输出文件描述符,shell会在脚本退出时自动关闭它们。然而在有些
情况下,你需要在脚本结束前手动关闭文件描述符。
要关闭文件描述符,将它重定向到特殊符号&-。脚本中看起来如下:exec 3>&-
该语句会关闭文件描述符3,不再在脚本中使用它。这里有个例子来说明当你尝试使用已关
闭的文件描述符时会怎样。
$ cat badtest
#!/bin/bash
# testing closing file descriptors
exec 3> test17file
echo "This is a test line of data" >&3
exec 3>&-
echo "This won't work" >&3
$ ./badtest
./badtest: 3: Bad file descriptor
$ 一旦关闭了文件描述符,就不能在脚本中向它写入任何数据,否则shell会生成错误消息。
在关闭文件描述符时还要注意另一件事。如果随后你在脚本中打开了同一个输出文件,shell
会用一个新文件来替换已有文件。这意味着如果你输出数据,它就会覆盖已有文件。考虑下面这
个问题的例子。
$ cat test17
#!/bin/bash
#testing closing file descriptors
exec 3> test17file
echo "This is a test line of data" >&3
exec 3>&-
cat test17file
exec 3> test17file
echo "This'll be bad" >&3
$ ./test17
This is a test line of data
$ cat test17file
This'll be bad
$ 15.5 列出未关闭的文件描述符
你能用的文件描述符只有9个,你可能会觉得这没什么复杂的。但有时要记住哪个文件描述
符被重定向到了哪里很难。为了帮助你理清条理,bash shell提供了lsof命令。$$可以读取当前程序运行的的PID,-a
对其他两个选项的输出做AND运算
/usr/sbin/lsof -a -p $$ -d 0,1,2
# lsof的默认输出
COMMAND 正在运行的命令名的前9个字符
PID 进程的PID
USER 进程属主的登录名
FD 文件描述符号以及访问类型(r代表读,w代表写,u代表读写)
TYPE 文件的类型(CHR代表字符型,BLK代表块型,DIR代表目录,REG代表常规文件)
DEVICE 设备的设备号(主设备号和从设备号)
SIZE 如果有的话,表示文件的大小
NODE 本地文件的节点号
NAME 文件名与STDIN、STDOUT和STDERR关联的文件类型是字符型。因为STDIN、STDOUT和STDERR文
件描述符都指向终端,所以输出文件的名称就是终端的设备名。所有3种标准文件都支持读和写
(尽管向STDIN写数据以及从STDOUT读数据看起来有点奇怪)。
现在看一下在打开了多个替代性文件描述符的脚本中使用lsof命令的结果。
$ cat test18
#!/bin/bash
# testing lsof with file descriptors
exec 3> test18file1
exec 6> test18file2
exec 7< testfile
/usr/sbin/lsof -a -p $$ -d0,1,2,3,6,7
$ ./test18
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
test18 3594 rich 0u CHR 136,0 2 /dev/pts/0
test18 3594 rich 1u CHR 136,0 2 /dev/pts/0
test18 3594 rich 2u CHR 136,0 2 /dev/pts/0
18 3594 rich 3w REG 253,0 0 360712 /home/rich/test18file1
18 3594 rich 6w REG 253,0 0 360715 /home/rich/test18file2
18 3594 rich 7r REG 253,0 73 360717 /home/rich/testfile
$ 该脚本创建了3个替代性文件描述符,两个作为输出(3和6),一个作为输入(7)。在脚本
运行lsof命令时,可以在输出中看到新的文件描述符。我们去掉了输出中的第一部分,这样你
就能看到文件名的结果了。文件名显示了文件描述符所使用的文件的完整路径名。它将每个文件
都显示成REG类型的,这说明它们是文件系统中的常规文件。
(第一遍不是很懂)
15.6 组织命令输出
如果在运行在后台的脚本出现错误消息,shell会通过电子邮件将它们发给进程的属主。这
会很麻烦,尤其是当运行会生成很多烦琐的小错误的脚本时。
要解决这个问题,可以将STDERR重定向到一个叫作null文件的特殊文件。null文件跟它的名
字很像,文件里什么都没有。shell输出到null文件的任何数据都不会保存,全部都被丢掉了。
在Linux系统上null文件的标准位置是/dev/null。你重定向到该位置的任何数据都会被丢掉,
不会显示。
cat /dev/null/ > test18
# 这时候test18文件就是空的
15.7 创建临时文件
15.7.1 创建本地临时文件
mktemp kirk.XXXXXX # 这里面的XXXXXX是必须的这是在本地目录创建临时文件
15.7.2 在/temp/创建临时文件
mktemp -t kirk.XXXXXX在/temp/目录下创建了一个临时文件夹
15.7.3 创建临时目录
mktemp -d kirk.XXXXXX在/temp/目录下创建文件夹
15.8 记录消息
有时候想把STDOUT输出到指定文件,又想输出到屏幕上,可以考虑使用tee命令,但是tee命令会覆盖以前的内容
但是如果你想把输出追加到文件中需要使用-a选项
15.9 实战
稍后完善
16. 控制脚本
16.1 处理信号
linux利用信号与运行在系统中的进程进行通信,
16.1.1 重温linux信号
linux可以与程序产生30多种信号
信 号 值 描 述
1 SIGHUP 挂起进程
2 SIGINT 终止进程
3 SIGQUIT 停止进程
9 SIGKILL 无条件终止进程
15 SIGTERM 尽可能终止进程
17 SIGSTOP 无条件停止进程,但不是终止进程
18 SIGTSTP 停止或暂停进程,但不终止进程
19 SIGCONT 继续运行停止的进程默认情况下,bash shell会忽略收到的任何SIGQUIT (3)和SIGTERM (5)信号(正因为这样,
交互式shell才不会被意外终止)。但是bash shell会处理收到的SIGHUP (1)和SIGINT (2)信号。
如果bash shell收到了SIGHUP信号,比如当你要离开一个交互式shell,它就会退出。但在退
出之前,它会将SIGHUP信号传给所有由该shell所启动的进程(包括正在运行的shell脚本)。
16.1.2 生成信号
- crtl+C 生成SIGINT(2)终止进程信号
- crtl+Z 生成SIGTSTP(17)停止shell中运行的任何进程
停止shell中运行的任何进程。停止(stopping)进程,跟终止(terminating)进程不同:停止进程会让程序继续保留在内存中,并能从上次停止的位置
继续运行。在16.4节中,你会了解如何重启一个已经停止的进程。可以使用ps -l命令来显示各进程
16.1.3 捕获信号
trap命令允许你来指定shell
脚本要监看并从shell中拦截的Linux信号。如果脚本收到了trap命令中列出的信号,该信号不再
由shell处理,而是交由本地处理。
#!/bin/bash
# Testing signal trapping
#
trap "echo ' Sorry! I have trapped Ctrl-C'" SIGINT
#
echo This is a test script
#
count=1
while [ $count -le 10 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done该脚本使用trap命令捕获信号,使我们编写的脚本处理信号而不是shell处理
当使用ctrl-C时候,我们脚本的trap命令就会处理这个SIGINT信号
16.1.4 捕获脚本退出
除了在shell脚本中捕获退出,你也可以在shell退出时就行捕获,这是shell完成任务时一种执行命令的一种方式,要捕获shell的退出只需要在trap命令后面加上EXIT信号就行.
#!/bin/bash
# Trapping the script exit
#
trap "echo Goodbye..." EXIT
#
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#1. 脚本正常执行完,然后执行了trap脚本
#2. ctrl-c 命令也会触发退出命令,ctrl-c之后就不会执行剩余代码。16.1.5 修改或移除捕获
捕获或移除这节一句话概括就是设置trap命令的有效期,或者叫生命周期。也可以删除已设置好的捕获。只需要在trap命令与希望恢复默认行为的信号列表之间加上
两个破折号就行了,
#!/bin/bash
# Modifying a set trap
#
trap "echo ' Sorry... Ctrl-C is trapped.'" SIGINT
#
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#
trap "echo ' I modified the trap!'" SIGINT
#
count=1
while [ $count -le 5 ]
do
echo "Second Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
$ ./test3.sh
Loop #1
Loop #2
Loop #3
^C Sorry... Ctrl-C is trapped.
Loop #4
Loop #5
Second Loop #1
Second Loop #2
^C I modified the trap!
Second Loop #3
Second Loop #4
Second Loop #5
$
也可以在trap命令后使用单破折号来恢复信号的默认行为
移除信号捕获后,脚本按照默认行为来处理SIGINT信号,也就是终止脚本运行。但如果信
号是在捕获被移除前接收到的,那么脚本会按照原先trap命令中的设置进行处理。
在本例中,第一个Ctrl+C组合键用于提前终止脚本。因为信号在捕获被移除前已经接收到了,
脚本会照旧执行trap中指定的命令。捕获随后被移除,再按Ctrl+C就能够提前终止脚本了。
总结:
修改了信号捕获之后,脚本处理信号的方式就会发生变化。但如果一个信号是在捕获被修改前接收到的,那么脚本仍然会根据最初的trap命令进行处理。trap根绝接收到信号会
立刻从sleep中唤醒
16.2 以后台模式运行脚本
16.2.1 后台运行脚本
当&符放到命令后时,它会将命令和bash shell分离开来,然后给分配一个调度号和PID号,在后台模式中,
进程运行时不会和终端会话上的STDIN、STDOUT以及STDERR关联
16.2.2 运行多个后台作业
当我们同时运行多个后台运行程序的时候,然后使用ps命令这时候发现很多进程与pts/0绑定着,如果终端会话退出,那么后台进程也会随之退出
16.2.3 在非控制台下运行程序
有时你会想在终端会话中启动shell脚本,然后让脚本一直以后台模式运行到结束,即使你退
出了终端会话。这可以用nohup命令来实现.和普通后台进程一样,shell会给命令分配一个作业号,Linux系统会为其分配一个PID号。区
别在于,当你使用nohup命令时,如果关闭该会话,脚本会忽略终端会话发过来的SIGHUP信号。
由于nohup命令会解除终端与进程的关联,进程也就不再同STDOUT和STDERR联系在一起。
为了保存该命令产生的输出,nohup命令会自动将STDOUT和STDERR的消息重定向到一个名为
nohup.out的文件中。
当多个命令同时使用nohup命令时候,且同时修改nohup命令的时候,他们会追加到nohup.out命令
# 命令demo
nohup ./test1.sh &16.4 作业控制
16.4.1 查看作业
jobs命令可以查看分配给shell的作业,jobs -l可以查看完整的PID
参数 描述
-l 列出进程的PID以及作业号
-n 只列出上次shell发出的通知后改变了状态的作业
-p 只列出作业的PID
-r 只列出运行中的作业
-s 只列出已停止的作业
#你可能注意到了jobs命令输出中的加号和减号。带加号的作业会被当做默认作业。在使用
#作业控制命令时,如果未在命令行指定任何作业号,该作业会被当成作业控制命令的操作对象。
#当前的默认作业完成处理后,带减号的作业成为下一个默认作业。任何时候都只有一个带加
#号的作业和一个带减号的作业,不管shell中有多少个正在运行的作业。16.4.2 重启停止的作业
在bash作业控制中,可以将已停止的作业作为后台进程或前台进程重启。前台进程会接管你
当前工作的终端,所以在使用该功能时要小心了。
要以后台模式重启一个作业,可用bg命令加上作业号
[1]+ Stopped ./test11.sh
$ bg # 这时候就重启了./test11.sh 作业,以后台模式
# 如果重启多个就是用bg 2
# 要以前台模式重启作业,可用带有作业号的fg命令。
16.5 调整谦让度
- 在多任务操作系统中(Linux就是),内核负责将CPU时间分配给系统上运行的每个进程。调
度优先级(scheduling priority)是内核分配给进程的CPU时间(相对于其他进程)。在Linux系统
中,由shell启动的所有进程的调度优先级默认都是相同的。 - 调度优先级是个整数值,从-20(最高优先级)到+19(最低优先级)。默认情况下,bash shell
以优先级0来启动所有进程。
最低值20是最高优先级,而最高值19是最低优先级,这太容易记混了。只要记住那句俗
语“好人难做”就行了。 - 有时你想要改变一个shell脚本的优先级。不管是降低它的优先级(这样它就不会从占用其他
进程过多的处理能力),还是给予它更高的优先级(这样它就能获得更多的处理时间),你都可以
通过nice命令做到。
16.5.1 nice 命令
nice命令允许你设置命令启动时的调度优先级。要让命令以更低的优先级运行,只要用nice
的-n命令行来指定新的优先级级别。
nice -n 10 ./test4.sh > test4.out & # 注意,必须将nice命令和要启动的命令放在同一行中。一旦用nice命令设置了优先级,就不可以用nice重新设置优先级
16.5.2 renice 命令
有时你想改变系统上已运行命令的优先级。这正是renice命令可以做到的。它允许你指定
运行进程的PID来改变它的优先级。
renice -n 10 -p 5055 # -p应该是指进程renice命令会自动更新当前运行进程的调度优先级。和nice命令一样,renice命令也有一
些限制:
- 只能对属于你的进程执行renice;
- 只能通过renice降低进程的优先级;
- root用户可以通过renice来任意调整进程的优先级。
如果想完全控制运行进程,必须以root账户身份登录或使用sudo命令
16.6 定时运行作业
16.6.1 用at命令来计划执行作业
at命令的格式
at命令只执行一次,区别于cronat [-f filename] time # -f 后面用来指定读取命令time : 参数指定运行时间,如果错过就会在第二天同一时间再运行
time能识别多种时间格式- 标准小时和分钟的格式,比如10:15
- AM/PM指示符,比如10:15PM
- 特定可命名时间,比如now,noon,midnight,或者teatime(4 PM)
- 标准日期格式,比如MMDDYY,MM/DD/YY,DD.MM.YY
- 文本日期比如jul 4或Dec 25 加不加年份都可以。
- 你也可以指定增量时间
- 当前时间+25 min
- 明天10:15 PM
- 10:15+7天
通过at命令都会被提交到作业队列,针对不同的优先级存在26种不同的作业队列,使用
a-z和A-Z来指代,即使通过at命令提交过作业,也可以通过-q参数指定不同的队列字母
作业队列的字母排序越高,作业运行的优先级就越低(更高的nice值)。默认情况下,at的
作业会被提交到a作业队列
获取作业的输出
at命令利用sendemail应用程序发送邮件,这样其实很麻烦,但是可以将输出重定向到STDOUT
和STDERR,再如果可以使用-M屏蔽输出列出等待的作业
atq命令可以查看系统中哪些作业处于等待状态删除作业
atrm删除等待种的作业
#demo
atq 命令可以列出作业编号
atrm 作业编号 # 只能删除你提交的作业,不能删除其他人的。16.6.2 安排需要定期执行的脚本
cron时间表
min hour dayofmonth month dayofweek command比如你想每天10:15运行一个命令可以使用cron时间表条目
min hour dayofmonth month dayofweek command 15 10 * * * command但是如果想在每周一的下午4点15分执行,可写为
15 16 * * 1 command可以用三字符的文本值(mon、tue、wed、thu、fri、sat、sun)
或数值(0为周日,6为周六),dayofmonth表项指定月份中的日期值(1~31)。聪明的读者可能会问如何设置一个在每个月的最后一天执行的命令,因为你无法设置
dayofmonth的值来涵盖所有的月份。这个问题困扰着Linux和Unix程序员,也激发了不少解
决办法。常用的方法是加一条使用date命令的if-then语句来检查明天的日期是不是01:00 12 * * * if [ `date +%d -d tomorrow` = 01 ] ; then ; command它会在每天中午12点来检查是不是当月的最后一天,如果是,cron将会运行该命令。
命令必须要指定要运行的脚本名字,或者添加重定向符号
cron程序会用提交作业的用户账户运行该脚本。因此,你必须有访问该命令和命令中指定的
输出文件的权限。构建cron时间表
可以使用crontab -l来处理cron时间表
默认情况下,用户的cron时间表文件并不存在。要为cron时间表添加条目,可以用-e选项。
在添加条目时,crontab命令会启用一个文本编辑器(参见第10章),使用已有的cron时间表作
为文件内容(或者是一个空文件,如果时间表不存在的话)。浏览cron目录
如果你创建的脚本对精确的执行时间要求不高,用预配置的cron脚本目录会更方便。有4个
基本目录:hourly、daily、monthly和weekly。- /etc/cron.daily
- /etc/cron.hourly
- /etc/cron.monthly
- /etc/cron.weekly
因此,如果脚本需要每天运行一次,只要将脚本复制到daily目录,cron就会每天执行它
anacron程序
如果某个作业在cron时间表中安排运行的时间已到,但这时候Linux系统处于关机状态,那么
这个作业就不会被运行。当系统开机时,cron程序不会再去运行那些错过的作业。要解决这个问
题,许多Linux发行版还包含了anacron程序。
anacron
程序只会处理位于cron目录的程序,比如/etc/cron.monthly。它用时间戳来决定作业
是否在正确的计划间隔内运行了。每个cron目录都有个时间戳文件,该文件位于/var/spool/anacron。
sudo cat /var/spool/anacron/cron.monthly
20150626anacron程序使用自己的时间表(通常位于/etc/anacrontab)来检查作业目录。
anacron时间表的基本格式和cron时间表略有不同:
period delay identifier commandperiod条目定义了作业多久运行一次,以天为单位。anacron程序用此条目来检查作业的时间
戳文件。delay条目会指定系统启动后anacron程序需要等待多少分钟再开始运行错过的脚本。
command条目包含了run-parts程序和一个cron脚本目录名。run-parts程序负责运行目录中传给它的
任何脚本。
注意,anacron不会运行位于/etc/cron.hourly的脚本。这是因为anacron程序不会处理执行时间
需求小于一天的脚本。
identifier条目是一种特别的非空字符串,如cron-weekly。它用于唯一标识日志消息和错误
邮件中的作业。
16.6.3 使用新shell启动脚本
.bashrc文件通常也是通过某个bash启动文件来运行的。因为.bashrc文件会运行两次:一次是
当你登入bash shell时,另一次是当你启动一个bash shell时。如果你需要一个脚本在两个时刻都得
以运行,可以把这个脚本放进该文件中。
17. 创建函数
17.1 基本的脚本函数
17.1.1 创建函数
有两种方式定义函数
function name(){
command;
}另一种更像是高级编程语言定义函数
name(){
command;
}17.1.2 使用函数
正常情况就像是其他高级语言一样,但是bash的函数有个特殊情况。如果是重定义了一个旧函数,
那么就会覆盖以前的定义,正如下面的例子
#!/bin/bash
# testing using a duplicate function name
function func1 {
echo "This is the first definition of the function name"
}
func1
function func1 {
echo "This is a repeat of the same function name"
}
func1
echo "This is the end of the script"
17.2 返回值
17.2.1 默认退出状态码
即使是在函数中,command1,command2,command3 中的1,2执行错误,3成功了,那么退出
状态码也是0.所以说默认退出状态码是很危险的。
17.2.2 使用return命令
return的demo如下
#!/bin/bash
# using the return command in a function
function dbl {
read -p "Enter a value: " value
echo "doubling the value"
return $[ $value * 2 ]
}
dbl
echo "The new value is $?"
dbl函数会将$value的值翻倍,然后返回,有两点要小心
- 记住,函数一结束就取返回值
- 记住,退出码必须是0~255
也可以返回字符串和较大的数值,可以看下一节
17.2.3 使用函数输出
#!/bin/bash
# using the echo to return a value
function dbl {
read -p "Enter a value: " value
echo $[ $value * 2 ]
}
result=$(dbl)
echo "The new value is $result"
#$ ./test5b
#Enter a value: 200
#The new value is 400可以看到是将一函数结果执行取值运算得到返回值。
通过这种技术,你还可以返回浮点值和字符串值。这使它成为一种获取函数返回值的强
大方法。
17.3 在函数中使用变量
17.3.1 向函数传递参数
错误传递参数代码
#!/bin/bash
# trying to access script parameters inside a function
function badfunc1 {
echo $[ $1 * $2 ]
}
if [ $# -eq 2 ]
then
value=$(badfunc1)
echo "The result is $value"
else
echo "Usage: badtest1 a b"
fi
# $ ./badtest1
# Usage: badtest1 a b
# $ ./badtest1 10 15
# ./badtest1: * : syntax error: operand expected (error token is "*
# ")
# The result is
# 脚本的$1和$2和函数调用的$1,$2变量是不一样的接下来是正确的代码
#!/bin/bash
# trying to access script parameters inside a function
function func7 {
echo $[ $1 * $2 ]
}
if [ $# -eq 2 ]
then
value=$(func7 $1 $2)
echo "The result is $value"
else
echo "Usage: badtest1 a b"
fi
#$
#$ ./test7
#Usage: badtest1 a b
#$ ./test7 10 15
#The result is 150
通过将$1和$2变量传给函数,它们就能跟其他变量一样供函数使用了
17.3.2 在函数中处理变量
- 全局变量
全局变量被覆盖
#!/bin/bash
# demonstrating a bad use of variables
function func1 {
temp=$[ $value + 5 ]
result=$[ $temp * 2 ]
}
temp=4
value=6
func1
echo "The result is $result"
if [ $temp -gt $value ]
then
echo "temp is larger"
else
echo "temp is smaller"
fi
#$ ./badtest2
#The result is 22
#temp is larger
# 说明TEMP变量受到了影响,读和写都是改变的全局变量- 局部变量
local关键字保证了变量只局限在该函数中。如果脚本中在该函数之外有同样名字的变量,
那么shell将会保持这两个变量的值是分离的
#!/bin/bash
# demonstrating the local keyword
function func1 {
local temp=$[ $value + 5 ]
result=$[ $temp * 2 ]
}
temp=4
value=6
func1
echo "The result is $result"
if [ $temp -gt $value ]
then
echo "temp is larger"
else
echo "temp is smaller"
fi
#$ ./test9
#The result is 22
#temp is smaller if里面的$temp参数是全局的,因为已经在函数外
17.4 数组变量和函数
直接传入只会传入数组的第一个值,可考虑如下方法
#!/bin/bash
# array variable to function test
function testit {
local newarray
newarray=(;'echo "$@"')
echo "The new array value is: ${newarray[*]}"
}
myarray=(1 2 3 4 5)
echo "The original array is ${myarray[*]}"
testit ${myarray[*]}
#$
#$ ./test10
#The original array is 1 2 3 4 5
#The new array value is: 1 2 3 4 5
第二种也可以
#!/bin/bash
# adding values in an array
function addarray {
local sum=0
local newarray
newarray=($(echo "$@"))
for value in ${newarray[*]}
do
sum=$[ $sum + $value ]
done
echo $sum
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]})
result=$(addarray $arg1)
echo "The result is $result"
#$ ./test11
#The original array is: 1 2 3 4 5
#The result is 15 17.4.2 从函数中返回数组
#!/bin/bash
# returning an array value
function arraydblr {
local origarray
local newarray
local elements
local i
origarray=($(echo "$@"))
newarray=($(echo "$@"))
elements=$[ $# - 1 ]
for (( i = 0; i <= $elements; i++ ))
{
newarray[$i]=$[ ${origarray[$i]} * 2 ]
}
echo ${newarray[*]}
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]})
result=($(arraydblr $arg1))
echo "The new array is: ${result[*]}"
arraydblr函数使用echo语句来输出每个数组元素的值。脚本用arraydblr函数的输出来
重新生成一个新的数组变量。
17.5 函数递归
#!/bin/bash
# using recursion
function factorial {
if [ $1 -eq 1 ]
then
echo 1
else
local temp=$[ $1 - 1 ]
local result=$(factorial $temp)
echo $[ $result * $1 ]
fi
}
read -p "Enter value: " value
result=$(factorial $value)
echo "The factorial of $value is: $result"
#$ ./test13
#Enter value: 5
#The factorial of 5 is: 120
17.6 创建库
问题出在shell函数的作用域上。和环境变量一样,shell函数仅在定义它的shell会话内有效。如果你在shell命令行界面的提示符下运行myfuncs shell脚本,shell会创建一个新的shell并在其中运行这个脚本。它会为那个新shell定义这三个函数,但当你运行另外一个要用到这些函数的脚本时,它们是无法使用的
#!/bin/bash
# using a library file the wrong way
./myfuncs
result=$(addem 10 15)
echo "The result is $result"
$ ./badtest4
./badtest4: addem: command not found
The result is 使用函数库的关键在于source命令。source命令会在当前shell上下文中执行命令,而不是
创建一个新shell。可以用source命令来在shell脚本中运行库文件脚本。这样脚本就可以使用库中的函数了。
17.7 在命令行上使用函数
和在shell脚本中将脚本函数当命令使用一样,在命令行界面中你也可以这样做。这个功能很,不错,因为一旦在shell中定义了函数,你就可以在整个系统中使用它了,无需担心脚本是不是在PATH环境变量里。重点在于让shell能够识别这些函数。有几种方法可以实现。
17.7.1 在命令上创建函数
简单点直接定义
function divem { echo $[ $1 / $2 ]; }另一种采用多行式
$ function multem { > echo $[ $1 * $2 ] > } $ multem 2 5
17.7.2 在.bashrc 文件中定义函数
直接定义函数
$ cat .bashrc # .bashrc # Source global definitions if [ -r /etc/bashrc ]; then . /etc/bashrc fi function addem { echo $[ $1 + $2 ] }读取函数文件
直接定义在特地的文件内,然后读取在.bashrc中读取
17.8 实例
17.8.1 下载安装第三方库
17.8.2 构建库
下载,编译,安装。这里面涉及到CMAKE的相关知识
17.8.3 shtool库函数
这里就是介绍些shtool提供的一些函数,后面会很有用,但是需要与公司内的环境做适配
17.8.4 使用库
编译,安装完后,就可以在脚本中使用了
18. 图形化界面中脚本编程
暂时不需要
19.初识sed和gawk
你得熟悉Linux中的sed和gawk工具。这两个工具能够极大简化需要进行的数据处
理任务。
19.1 文本处理
19.1.1 sed编辑器
sed编辑器被称作流编辑器(stream editor),和普通的交互式文本编辑器恰好相反。在交互式
文本编辑器中(比如vim),你可以用键盘命令来交互式地插入、删除或替换数据中的文本。流编
辑器则会在编辑器处理数据之前基于预先提供的一组规则来编辑数据流。
- 一次输入一行
- 根据所提供的编辑器命令匹配数据。
- 按照命令修改流中数据
- 将最后结果输出到STDOUT
sed options script file
echo 'this is a test' | sed 's/test/big test/' 使用s命令将test替换为big test
sed 's/dog/cat/' data.txt 这是修改文件中dog为cat
sed -e 's/brown/red; s/blue/yellow/' data/txt- 在命令行定义编辑器命令
echo "This is a test" | sed 's/test/big test/' 这里使用了sed的s命令,是指替换字符串,符合replace A B,用B替换A.重要的是,要记住,
sed编辑器并不会修改文本文件的数据。它只会将修改后的数据发送到STDOUT。如果你查看原来
的文本文件,它仍然保留着原始数据。
2. 在命令行使用多个编辑器命令
sed -e 's/brown/green/; s/dog/cat/' data1.txt 这种情况一定要加分号,也可以使用
$ sed -e '
> s/brown/green/
> s/fox/elephant/
> s/dog/cat/' data1.txt
必须记住,要在封尾单引号所在行结束命令。bash shell一旦发现了封尾的单引号,就会执行
命令。开始后,sed命令就会将你指定的每条命令应用到文本文件中的每一行上。
- 从文件中读取编辑器命令
sed -f script.sed data.txt
# 命令文件
$ cat script1.sed
s/brown/green/
s/fox/elephant/
s/dog/cat/19.1.2 gawk程序
虽然sed很好,很强大,但是还是有局限性,通常你需要一个用来处理文件中的数据的更高级工具,
它能提供一个类编程环境来修改和重新组织文件中的数据。这正是gawk能够做到的。
提供了一种编程语言而不只是编辑器命令。在gawk编程语言中,你可以做下面的事情:
- 定义变量来保存数据;
- 使用算术和字符串操作符来处理数据;
- 使用结构化编程概念(比如if-then语句和循环)来为数据处理增加处理逻辑;
- 通过提取数据文件中的数据元素,将其重新排列或格式化,生成格式化报告。
基本格式
gawk options program file可用选项
-F fs 指定行中划分数据字段的字段分隔符 -f file 从指定的文件中读取程序 -v var=value 定义gawk程序中的一个变量及其默认值 -mf N 指定要处理的数据文件中的最大字段数 -mr N 指定数据文件中的最大数据行数 -W keyword 指定gawk的兼容模式或警告等级从命令行读取程序脚本
gawk '{print "Hello World!"}',可能让你失望了,什么都没有,gawk需要从STDIN读取数据,所以你输入任何字符都会返回hello world,
Ctrl+D组合键会在bash中产生一个EOF字符。这个组合键能够终止该gawk使用数据字段变量
gawk会将如下变量分配给它在文本行中发现的数据字段:
$0代表整个文本行;
$1代表文本行中的第1个数据字段;
$2代表文本行中的第2个数据字段;
$n代表文本行中的第n个数据字段。
自动为文件每一行数据分配一个变量gawk ‘{print $1}’ data2.txt 数据文件中每一行的第一个字符
gawk -F: '{print $1}' /etc/passwd在程序脚本中使用多个命令
"my name is rich" | gawk '{$4="Christine"; print $0}', 给第四个字段名赋值,并输出文本名 ,
注意, gawk程序在输出中已经将原文本中的第四个数据字段替换成了新值。如果不指定文件名就会从标准输入等待输入
也可以多行$ gawk '{ > $4="Christine" > print $0}' $My name is Rich $My name is Christine从文件中读取程序
gawk -F: -f script2.gawk /etc/passwd cat script2.gawk {print $1 "'s home directory is " $6}
script2.gawk程序脚本会再次使用print命令打印/etc/passwd文件的主目录数据字段(字段变
量$6),以及userid数据字段(字段变量$1)。
$ cat script3
{
text = "'s home directory is "
print $1 text $6
} script3.gawk程序脚本定义了一个变量(text)来保存print命令中用到的文本字符串。注意,gawk
程序在引用变量值时并未像shell脚本一样使用美元
- 在处理数据前运行脚本
awk允许在执行脚本文件之前先执行某段特定程序BEGIN实现了这个功能
gawk 'BEGIN {print "Hello World!"}'但是执行这行命令就会立刻退出,如果想正常的程序脚本中处理数据,必须使用另一个脚本区域来定义程序
gawk 'BEGIN {print "The data3 File Contents:"}
> {print $0}' data3.txt 在gawk执行了BEGIN脚本后,它会用第二段脚本来处理文件数据。这么做时要小心,两段
脚本仍然被认为是gawk命令行中的一个文本字符串。你需要相应地加上单引号
- 处理数据后运行脚本
会在最后执行的一段程序代码
cat script4.gawk
BEGIN {
print "The latest list of users and shells"
print " UserID \t Shell"
print "-------- \t -------"
FS=":"
}
{
print $1 " \t " $7
}
END {
print "This concludes the listing"
} 19.2 sed 编辑器基础
19.2.1 更多的替换选项
- 替换标记
s/pattern/replacement/flags
一句话概括就是自定义替换范围,具体详情参考下面list
- 数字, 说明新文本将替换第几处的位置
- g,说明文本将替换所有
- p, 输出被替换命令修改过的行
- w file , 将结果输出到新文件中
sed 's/test/trial/w test.txt' data5.txt输出结果会打印到test.txt文件 - option 位置是 n 说明禁止输出
- 替换字符
在替换文件路径时候涉及到转义字符这样很影响阅读性
上面命令太难看,可以选择下面的方式sed 's/\/bin\/bash/\/bin\/csh/' /etc/passwdsed 's!/bin/bash!/bin/csh!' /etc/passwd
19.2.2 使用地址
sed编辑器中使用的命令会作用于文本数据的所有行。如果只想将命令作用
于特定行或某些行,则必须用行寻址(line addressing).
在sed编辑器中有两种形式的行寻址:
- 以数字形式表示行区间
- 用文本模式来过滤出行
- 数字方式的行寻址
sed编辑器会将文本流中的第一行编号为1,然后继续按顺序为接下来的行分配行号。
如果想修改2,3行可使用$ sed '2s/dog/cat/' data1.txt The quick brown fox jumps over the lazy dog The quick brown fox jumps over the lazy cat The quick brown fox jumps over the lazy dog The quick brown fox jumps over the lazy dog
如果想将命令作用到文本中从某行开始到结尾,可以用特殊地址——美元符sed '2,3s/dog/cat/' data1.txtsed '2,$s/dog/cat/' data1.txt The quick brown fox jumps over the lazy dog The quick brown fox jumps over the lazy cat The quick brown fox jumps over the lazy cat The quick brown fox jumps over the lazy cat - 使用文本模式过滤器
sed编辑器允许指定文本模式来过滤出命令要作用的行。必须用正斜线将要指定的pattern封起来。
sed编辑器会将该命令作用到包含指定文本模式的行上。
说白了就是支持正则表达式来匹配字符串sed '/Samantha/s/bash/csh/' /etc/passwd - 命令组合
如果需要在单行上执行多条命令,可以用花括号将多条命令组合在一起。sed编辑器会处理地址行处列出的每条命令。sed '3,${ > s/brown/green/ > s/lazy/active/ > }' data1.txt
19.2.3 删除行
sed 'd' data1.txt # 删除整个data1文件内容
sed '3d' data6.txt # 删除data6文件地三行
sed '3,$d' data6.txt # 删除data6文件第三行及后面的行
sed '/number 1/d' data6.txt # 删除第一行
sed '/1/,/3/d' data6.txt #也可以使用两个文本模式来删除某个区间内的行,但这么做时要小心。你指定的第一个模式会“打开”行删除功能,第二个模式会“关闭”行删除功能。sed编辑器会删除两个指定行之间的所有行(包括指定的行)。
$ cat data7.txt
This is line number 1.
This is line number 2.
This is line number 3.
This is line number 4.
This is line number 1 again.
This is text you want to keep.
This is the last line in the file.
$
$ sed '/1/,/3/d' data7.txt # 这个命令只会匹配数字的模式串
This is line number 4. 第二个出现数字“1”的行再次触发了删除命令,因为没有找到停止模式,所以就将数据流
中的剩余行全部删除了。当然,如果你指定了一个从未在文本中出现的停止模式,显然会出现另
外一个问题。
19.2.4 插入和附加文本
- 插入
- 附加
new line中的文本将会出现在sed编辑器输出中你指定的位置。记住,当使用插入命令时,
文本会出现在数据流文本的前面.
当使用附加命令时,文本会出现在数据流文本的后面。$ echo "Test Line 2" | sed 'i\Test Line 1'$ echo "Test Line 2" | sed 'a\Test Line 1' $ sed '3i\ > This is an inserted line.' data6.txt # 指定插入的位置 $ sed '3a\ > This is an appended line.' data6.txt # 指定append的位置 sed '$a\ > This is a new line of text.' data6.txt # append到最后一行 $ sed '1i\ > This is one line of new text.\ > This is another line of new text.' data6.txt # 要插入或附加多行文本,就必须对要插入或附加的新文本中的每一行使用反斜线,直到最后一行。
19.2.5 修改行
$ sed '3c\
> This is a changed line of text.' data6.txt
$ sed '/number 3/c\
> This is a changed line of text.' data6.txt 文本模式修改命令会修改它匹配的数据流中的任意文本行。
$ sed '/number 1/c\
> This is a changed line of text.' data8.txt # 正则表达式
sed '2,3c\
> This is a new line of text.' data6.txt # 用一行覆盖了2,3行19.2.6 转换命令
[address]y/inchars/outchars/ 如你在输出中看到的,inchars模式中指定字符的每个实例都会被替换成outchars模式中
相同位置的那个字符。
转换命令是一个全局命令,也就是说,它会文本行中找到的所有指定字符自动进行转换,而
不会考虑它们出现的位置。
$ echo "This 1 is a test of 1 try." | sed 'y/123/456/'19.2.7 回顾打印
- p命令用来打印文本行;
- 等号(=)命令用来打印行号;
- l(小写的L)命令用来列出行。
- 打印行
在命令行上用-n选项,你可以禁止输出其他行,只打印匹配文本模式的行。$ echo "this is a test" | sed 'p' # 打印原行 this is a test this is a test $ sed -n '/number 3/p' data6.txt # 打印匹配行 This is line number 3. $ sed -n '2,3p' data6.txt # 取范围 $ sed -n '/3/{ # 这个3是模式匹配 > p > s/line/test/p > }' data6.txt - 打印行号
$ sed '=' data1.txt $ sed -n '/number 4/{ > = > p > }' data6.txt # 模式匹配第四行,然后打印修改前数据 - 列出行
data10.txt文本文件包含了一个转义控制码来产生铃声。当用cat命令来显示文本文件时,你$ sed -n 'l' data9.txt # 可以打印出特殊字符,甚至是制表符 $ cat data10.txt This line contains an escape character. $ $ sed -n 'l' data10.txt This line contains an escape character. \a$ $
看不到转义控制码,只能听到声音(如果你的音箱打开的话)。但是,利用列出命令,你就能显
示出所使用的转义控制码
19.2.8 使 用 sed 处理文件
- sed支持写文件
filename可以使用相对路径或绝对路径,但不管是哪种,运行sed编辑器的用户都必须有文[address]w filename
件的写权限。地址可以是sed中支持的任意类型的寻址方式,例如单个行号、文本模式、行区间
或文本模式。$ sed -n '/Browncoat/w Browncoats.txt' data11.txt #文本模式匹配 $ sed '1,2w test.txt' data6.txt # 文件选址 - 从文件读取数据
filename参数指定了数据文件的绝对路径或相对路径。你在读取命令中使用地址区间,只
能指定单独一个行号或文本模式地址。sed编辑器会将文件中的文本插入到指定地址后。
将data12.txt的文件插入到 data6.txt文件流中第三行后面$ cat data12.txt This is an added line. This is the second added line. $ $ sed '3r data12.txt' data6.txt This is line number 1. This is line number 2. This is line number 3. This is an added line. This is the second added line. This is line number 4.
读取命令的另一个很酷的用法是和删除命令配合使用$ sed '/LIST/{ > r data11.txt > d > }' notice.std
20.正则表达式
20.1 什么是正则表达式
正则表达式就是某种模板(筛子),正则表达式是通过正则表达式引擎(regular expression engine)实现的。正则表达式引擎是
一套底层软件,负责解释正则表达式模式并使用这些模式进行文本匹配。
- POSIX基础正则表达式(basic regular expression,BRE)引擎
- POSIX扩展正则表达式(extended regular expression,ERE)引擎
20.2 定义BRE模式
20.2.1. 纯文本
echo "This is a test" | sed -n '/this/p' 这里面p是print,少了-n是打印两条,this没匹配到所以没有显示
空格也是普通的字符,比如sed -n / /p data.set
20.2.2 特殊字符
echo "3 / 2" | sed -n '///p' 正斜线也需要转义字符,故正确的是echo "3 / 2" | sed -n '/\//p'
20.2.3 锚定字符
^锚定字符
主要是锚定字符串行首。如果模式出现在行首之外的位置则不匹配,如果你将脱字符放到模式开头之外的其他位置,那么它就跟普通字符一样,不再是特殊字符了echo "This is ^ a test" | sed -n '/s ^/p'
``$锚定结尾
特殊字符美元符$定义了行尾锚点。将这个特殊字符放在文本模式之后来指明数据行必须以该文本模式结尾。echo "This is a good book" | sed -n '/book$/p'组合锚定
$ cat data4 this is a test of using both anchors # 这一行会被忽略 I said this is a test this is a test I'm sure this is a test. $ sed -n '/^this is a test$/p' data4 this is a test第二种情况
$ cat data5 This is one test line. This is another test line. $ sed '/^$/d' data5 This is one test line. This is another test line.定义的正则表达式模式会查找行首和行尾之间什么都没有的那些行。由于空白行在两个换行符之间没有文本,刚好匹配了正则表达式模式。sed编辑器用删除命令d来删除匹配该正则表达式模式的行,因此删除了文本中的所有空白行。这是从文档中删除空白行的有效方法
20.2.4 点字符
特殊字符点号用来匹配除换行符之外的任意单个字符。它必须匹配一个字符,如果在点号字符的位置没有字符,那么模式就不成立。
$ cat data6
This is a test of a line.
The cat is sleeping.
That is a very nice hat.
This test is at line four.
at ten o'clock we'll go home.
$ sed -n '/.at/p' data6
The cat is sleeping.
That is a very nice hat.
This test is at line four.
20.2.5 字符数组
点字符在模糊匹配上很有用,但是你想在某一位置上指定字符范围,那么字符数组就会很有用
$ sed -n '/[ch]at/p' data6
The cat is sleeping.
That is a very nice hat.
20.2.6 排除型字符
$ sed -n '/[
ch]at/p' data6
This test is at line four. 通过排除型字符组,正则表达式模式会匹配c或h之外的任何字符以及文本模式。由于空格字
符属于这个范围,它通过了模式匹配。但即使是排除,字符组仍然必须匹配一个字符,所以以at
开头的行仍然未能匹配模式
20.2.7 区间
想想匹配邮编那个case,实在是太麻烦,我们可以简化为区间表示
sed -n '/^[0-9][0-9][0-9][0-9][0-9]$/p' data8 也可以指定多个区间sed -n '/[a-ch-m]at/p' data6,该字符组允许区间ac、hm中的字母出现在at文本前
20.2.8 特殊的字符数组
#BRE特殊字符组
组 描 述
[[:alpha:]] 匹配任意字母字符,不管是大写还是小写
[[:alnum:]] 匹配任意字母数字字符0~9、A~Z或a~z
[[:blank:]] 匹配空格或制表符
[[:digit:]] 匹配0~9之间的数字
[[:lower:]] 匹配小写字母字符a~z
[[:print:]] 匹配任意可打印字符
[[:punct:]] 匹配标点符号
[[:space:]] 匹配任意空白字符:空格、制表符、NL、FF、VT和CR
[[:upper:]] 匹配任意大写字母字符A~Z 20.2.9 星号
在字符后面放置星号表明该字符必须在匹配模式的文本中出现0次或多次
$ echo "ik" | sed -n '/ie*k/p'
ik
$ echo "iek" | sed -n '/ie*k/p'
iek
$ echo "ieek" | sed -n '/ie*k/p'
ieek
$ echo "ieeek" | sed -n '/ie*k/p'另一个方便的特性是将点号特殊字符和星号特殊字符组合起来。这个组合能够匹配任意数量
的任意字符。它通常用在数据流中两个可能相邻或不相邻的文本字符串之间。
$ echo "this is a regular pattern expression" | sed -n '
> /regular.*expression/p'
this is a regular pattern expression 星号还能用在字符组上。它允许指定可能在文本中出现多次的字符组或字符区间。
$ echo "bt" | sed -n '/b[ae]*t/p'
bt
$ echo "bat" | sed -n '/b[ae]*t/p'
bat
$ echo "bet" | sed -n '/b[ae]*t/p'
bet
$ echo "btt" | sed -n '/b[ae]*t/p'
btt
$
$ echo "baat" | sed -n '/b[ae]*t/p'
baat
$ echo "baaeeet" | sed -n '/b[ae]*t/p'
baaeeet
$ echo "baeeaeeat" | sed -n '/b[ae]*t/p'
baeeaeeat
$ echo "baakeeet" | sed -n '/b[ae]*t/p'
$ 只要a和e字符以任何组合形式出现在b和t字符之间(就算完全不出现也行),模式就能够匹配。如果出现了字符组之外的字符,该模式匹配就会不成立。
AppendIndex
- re-read 意思是重新理解该章节